People start to talk about Zitgist: What is it? How does it work? When will it be released? Etc. This is the first article of a series to come that will explain the first portion of the service: the search query builder user interface. As you will see bellow, there are many considerations to take into account when dealing with the development of a semantic web search query builder.
The difference between a traditional search engine like Google and a semantic web search engine like Zitgist is that the aggregated, indexed and queried data is different. Google mostly use text files such as HTML, PDF, DOC, Etc., and Zitgist use RDF files from genuine or converted data sources.
This difference has a big impact on how users build queries to answer to their questions. Google users use keywords to try to define what they are searching for. Then the search engine will check in their database to find these keywords into the texts they aggregated and indexed.
The new paradigm introduced by semantic web search engine such as Zitgist is different: users will describe the characteristics of the subjects of their search instead of using keywords.
As you will see, the difference between using keywords and describing characteristics of subjects will have a great impact on the user interface used to build these search queries.
A first query

The first step is to choose which type of subject a user is searching for. In the first version of Zitgist, we let users choosing among some type of subjects: musical things such as artists, bands, albums, tracks, performances, or people, groups, projects, geographical locations, documents and discussion forums.
Once the user choose what he was searching for he has to describe the characteristics of that subject.
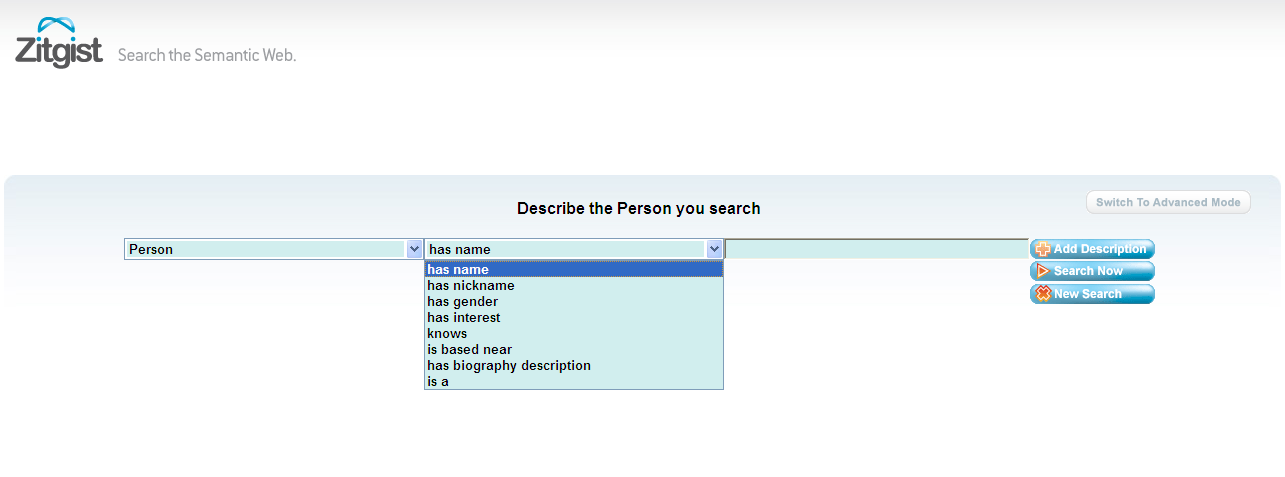
In that first example, the user tries to find a person. As you can see, there are some characteristics describing a person that can be defined by the user. Depending on the user interface (basic or advanced) more or less characteristic will be available for the description of that subject.
So the user chooses to search for a person that has the name “Chris” and that is interested in the “Semantic Web”.
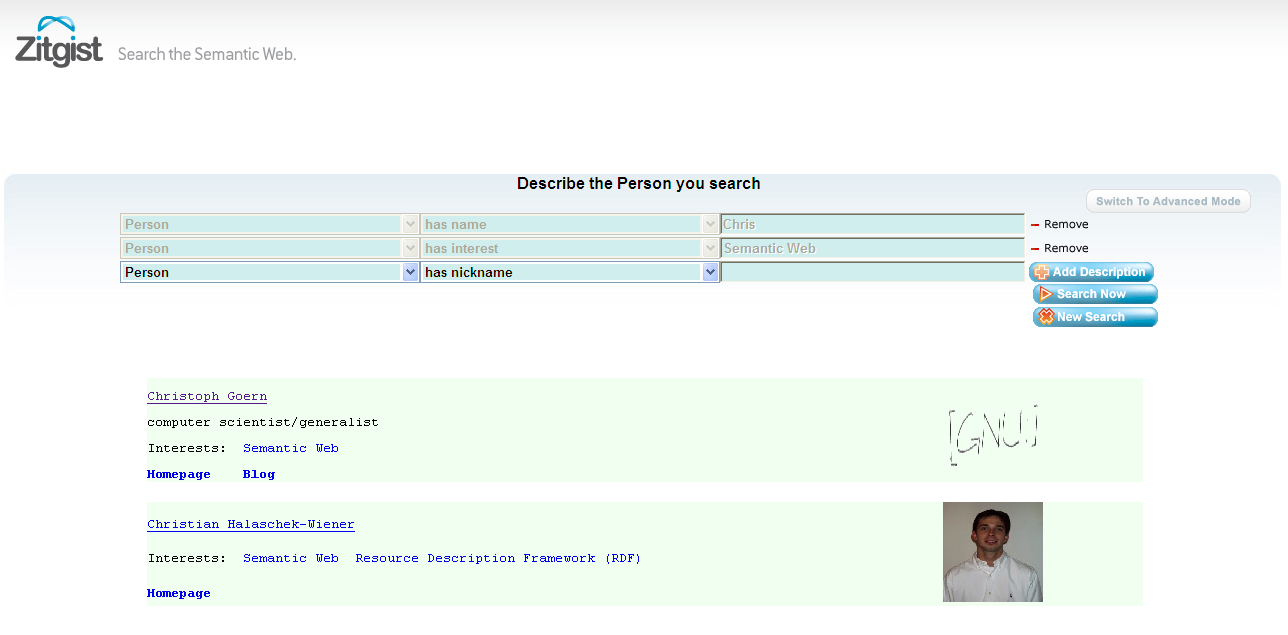
The search engine will then return results matching subjects know by Zitgist having these two characteristics.
Using Google, the user would have use the query string “chris semantic web” that has three distinct keywords: (1) “chris” (2) “semantic” and (3) “web”. The problem is that there is no relation between these keywords. Is he searching for someone named Chris that is working in the semantic web domain or that is interested in the semantic web? Is the user searching for something else? There is no way to know. The best Google can do, is putting their algorithmic magic into action to try to find what the user is searching for, and hoping it is really what he wants.
But for Zitgist, if the person [the subject of the search] defined himself as having the name Chris and having an interest in the Semantic Web (defining himself using RDF) than we will know that the results are definitely what the user is searching for.
Note: one of the next article will be dedicated to what will happens once a user get results from Zitgist.
Describing relationship between more than one subjects
The first example was quite simple. However Zitgist’s query builder interface take all its senses once we try to push it a little further.
How a user could easily describe a subject, with its own set of characteristics, that knows another subject, also with its own set of characteristics?

In this example, we have a user that search for a person knows as “Alice”. But he doesn’t search for any person named “Alice”, no. This user wants to find a person knows as “Alice” that know another person named “Bob”.
As you can see in the image above, it is quite easy to do using Zitgist. The user described the subject he wants to search for: “Alice”. This subject is a person with the name “Alice” that “knows” a person called “Bob”.
As you can see, the user interface changed its color when we introduced a new subject into the query [“Bob”]. That way, users can easily see which subject they are describing.
After that, the user could always add new characteristics to Bob. He could say that Bob is interesting in writing and that he lives near London for example.
In fact, the possibilities are endless.
One more step
What is interesting with the semantic web is that anybody can describe anything. One of these interesting example is when we start to think about Document. In fact, what are documents? What describe a Document? Etc.
A document can be described with an author, a creation data, a publication date, an editor, a publisher, its medium, etc. But its content can also be described such as its topics.
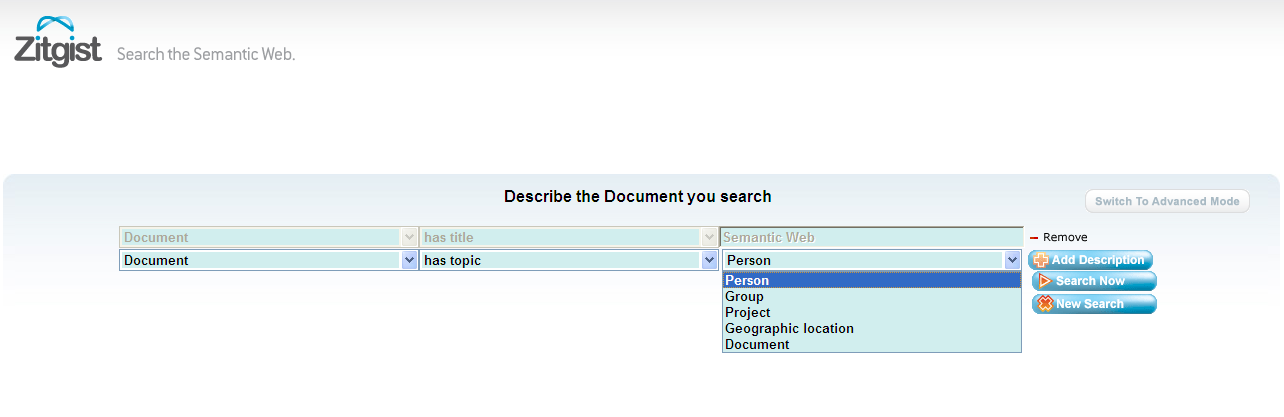
If someone describes one of the documents he created and that explicited the topic(s) of that document, Zitgist could easily find it that way:
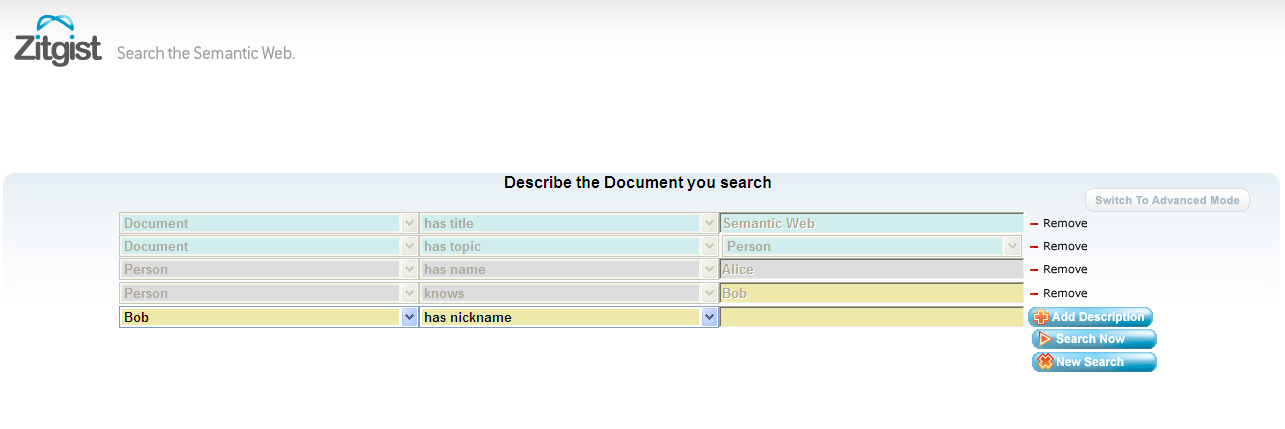
As you can see a user can search for a “Document” that as a “Person” named “Alice” that “knows” another person named “Bob” as the “Topic” of the “Document”.
So, if someone would start to describe novels that way, we could easily search for books where its protagonist is called Alice and that is living in London. Wouldn’t that be a terrific way to find books you could like to read? The only thing we need at the moment is people starting to describe books that way: hobbyist, authors or publishers.
We always knows the data we are manipulating
What is fantastic with the seman
tic web is that we always know what is the data we are manipulating. As you will see in next articles, this characteristic of the system is the main one when comes the time to talk about users interfaces. However, I will introduce it in this article using the query builder interface.

In the example above a user tries to find a geographic location near a certain place. However the question for the user here is: how should I describe that location? By a name? Which name? By a latitude and longitude? How to? Etc.
By the fact that we know what is the type of the data the user is looking for we can try to assist it with some widgets.
In the example above we know that the user is searching for a geographical location. Ultimately, a geographical location on Earth is defined by a longitude and latitude. So what we do is showing a map widget to the user. The only thing he will have to do is to click on the map to choose the location. That is it. The user interface widget is intuitive for users, and he doesn’t have to bother about how to describe the location.
Another example:

Now the user try to find a ” Music Artist” that “composed” “Albums” between “1980” and “1990”.
In such a case, how the user is supposed to describe that fact? Would he writes dates like “1980-01-03”? “1980-03-01″? ” 3 January 1980″? Etc…
Since Zitgist knows what the user is trying to describes, it only popup a small widget that will assists the user in the creation of its search query.
This is by far the greatest strength of the semantic web when come the time to talk about user interfaces. Since the interface knows what is the type of the data being manipulated, it can do a full of things to help users to do what he really want to. And what a user really want to do is certainly not asking questions like: how should I describe this thing, Etc.
And as you will see in next articles, this is just the beginning.
More information about Zitgist
There are a list of blogs post I wrote about Zitgist, explaining what the is project, its goals, its vision, its release, etc.
- Zitgist: a semantic web search engine
- Give it a name if you wish: the Semantic Web; but personally I don’t care.
Conclusion
Zitgist’s goal is not to be a replacement to traditional search engines such as Google. In short and middle term its goal is to be complementary to traditional search engines; to be another tool in Web users’ toolkit.
As you can see by the description of this semantic web search engine query interface, the semantic web and semantic web search engines like Zitgist will be quite useful to make some order, classify and search in all the data that has been created so far and that is yet to be created on the Web.
In the next articles I will continue to roll out what Zitgist is, where we are with the project and how it integrates into the semantic web that is now emerging on the Web.
The only thing you have to do is to sit down and check the show.
No I am wrong, the only thing you have to do is board the train and continue with us by asking question, making comments and suggestions, describing your data using RDF, letting Zitgist integrating it into its database, etc.
Welcome aboard.



![[Click to enlarge]](https://fgiasson.com/blog/wp-content/uploads/2007/03/.png){kind=link}