 |
Every link has a relation on the Semantic Web. Each time a person create a link from a web page to another web page, it does much more than simply linking… In fact, the Web and the Semantic Web are starting to mesh together. |
The meshing is occurring at the level of the URI, or more specifically at the level of the URL if we are talking about the Web. This is what I will show you in this post using a WordPress plug-in I developed using Zitgist technologies.
Motivations driving the development of the plug-in
The first objective of this project is to try to find out how people could integrate semantic web concepts and principles in the systems they daily use. How can we integrate the semantic web into Blogs for example? Is the use of semantic web technologies only good at publishing content in RDF? This is certainly one thing, but I doubt it is the only one. This is for that reason why I put some time in developing this prototype.
The second motivation is to create a good prototype of a system using Zitgist’s architecture to show people how they can take advantage of Zitgist to develop their projects; to make their vision a reality.
Some background thinking about the plug-in
On the Web, people mainly manipulate web page resources. They locate them on the Web using a unique locator, called a URL. On the semantic web on the other hand, people do not only manipulate documents; they manipulate many kind of Things, many kind of resources. They refer to them using URIs. The difference between a URI and a URL is that a URL is resolvable on the Web, but not necessarily a URI (in fact, a URI is the super-class of a URL). However, best practices suggest people to make URI resolvable (dereferencable) on the Web; in such a case a URI is a URL.
Anyway, all this to say that a URI in the semantic web can be a URL on the Web. There are many use cases emerging from that special digital environment. As an example, many people will use a Wikipedia Wiki Page URL as an URI for a topic, an interest, or for many other relations to these concepts. In such a case, the URL of a webpage is used to refer as a Concept. I don’t want to discuss about the basis of this, but it is a fact, and we have to handle it.
Introduction to the Zitgist WordPress Plug-in
This plug-in is quite simple in appearance, but has some really interesting results for users.
The only thing this plug-in does, is to show blog readers existing related data for a given URL and, in some case, to enable them to perform actions based on this data.
By example, if I make a link to Tim Berners-Lee‘s web page, a user could be interesting in having more information about Tim, directly from the article he is reading. Tim has many data related to him from the semantic web.
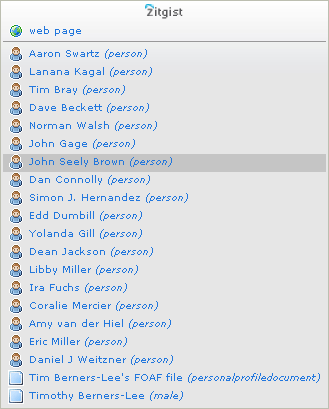
That is it. The plug-in display related information to links from a blog post. In this case, it is people Tim knows and Tim’s profile. The information is shown the users using a contextual menu. The data is requested to Zitgist’s systems and is displayed to the user. This is that simple, but how powerful?
The usefulness of the Zitgist WordPress Plug-in
The plug-in is quite useful in many ways. In fact, it instantly displays related information about a link to readers of the blog. From any blog post, a reader can easily jump to resources related to each link.
Some use cases
Above I said that a URL, a web link, could be much more than it usually appears. So bellow, I show a couple of use cases showing the potential behind the idea.
1. URL as a web page
What happen when a link from a blog post is a URL? Well, some things can happen, and there is an example:
Check it by yourself: The Bibliographic Ontology
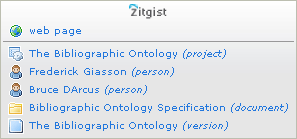
Here a user can check the webpage directly, or he can jump to related resources. These related resources come from the semantic web. The first one is the description of the project. The following two are the authors of the ontology. The last resources are documents related to the ontology and the “version” of the ontology.
2. URL as a dereferencable URI
For the non-initiated readers, I would suggest you to read this best practice tutorial explaining how to publish semantic web data on the web.
Sometimes (okay, not that much at the moment, but I hope people will start), people link to resource URIs (so, URL that can be dereferenced to get RDF data about the resource, or its web page representation if available).
Check it by yourself: URI referring to Frederick Giasson
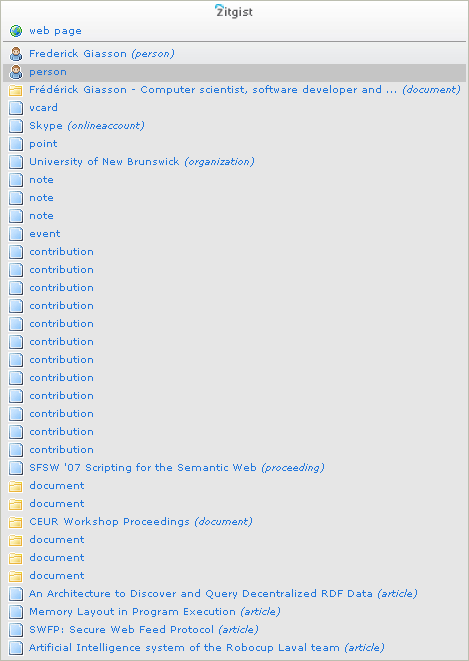
The result is that readers have directly access to my profile, articles I wrote, etc.
3. Actionable URL
Sometimes it can be really interesting to be able to act according to some URLs. One example is when a web page, or a resource (identified by a URI) refers to a thing that can be bought. By example: something that can be bought on Amazon.com:
Check it by yourself: Visualizing the Semantic Web

From the blog post, the reader can automatically buy the related resource on Amazon. This is only one possible action, but many others are possible; the only limit is imagination.
Conclusion
The simple links you create from your blog posts to other web pages have much more related information than you can think. Using this prototype Zitgist WordPress plug-in will explicit these links for your reader.
You only have to read some of my other blog posts to try it by yourself. Some results are quite impressing.
I will make this plug-in available for download sometime next week.
This idea has been promoted by Kingsley Idehen for some time now. He uses to call this idea enhanced anchors, or, a++. The idea is simple: enhancing anchors to explicit links to a certain resource (URI or URL), and optionally to perform some action on them.
This prototype is a first try in that direction. Many upgrades should follow so we really unveil the power of this new kind of linking; of this new way to relate things together, and to explicit these relations. Please report me any bug, issues, cross-browsers problems, comments, suggestions, etc.
