Zotero is a great FireFox add-on that lets its users find, search, edit and create citations they find on the Web while browsing it. All the power of Zotero resides in its “translation modules“. These modules will detect citations in various types of web pages. When it detects one of these citations, it will notify its users to give them the opportunity to save them.
What interest me is that Zotero already use some ontologies to export users’ citations libraries using RDF. When I noticed that I started to wonder: what could we do with Zotero now?
The Zotero vision
Zotero is the best-integrated citation tool for the Web I know. A phenomenal amount of citations can be discovered on the Web via Zotero users community.
Remember what we have done with the Semantic Radar a couple of months ago? This FireFox add-on was detecting SIOC RDF documents in Web page. Then I contacted Uldis Bojar to ask him to ping PingtheSemanticWeb.com each time a user was detecting a RDF file while he was browsing the Web. Now a good source of RDF data pinged to PTSW come from Semantic Radar users. This is a sort of “social semantic web discovering” technique.
What I would like to do is the same thing but for Zotero.
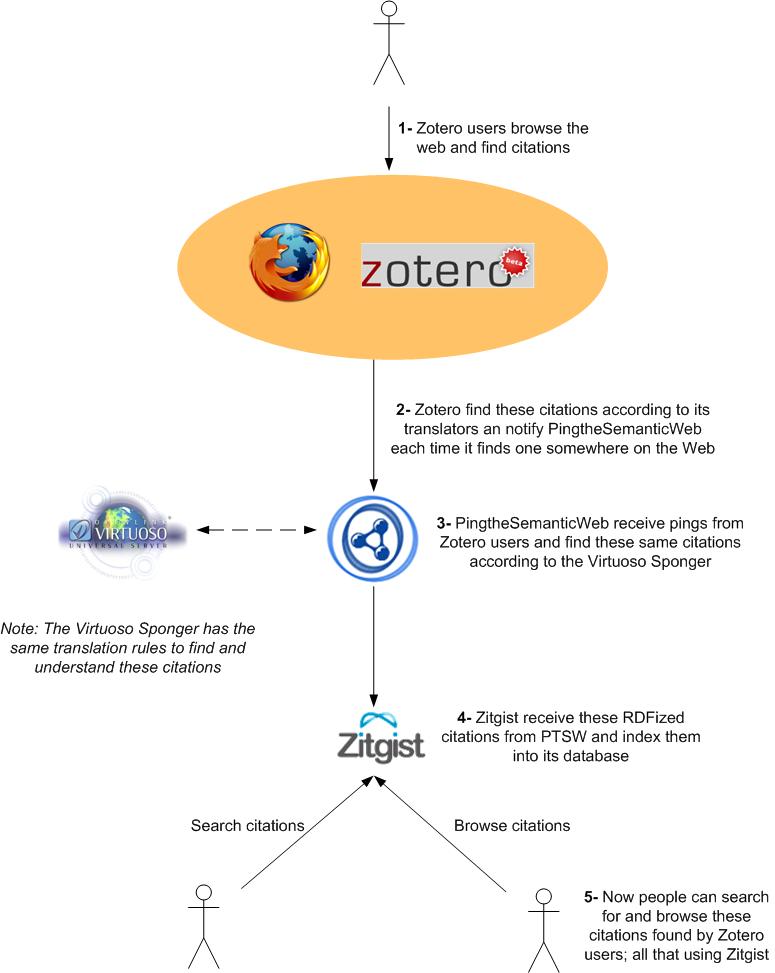
[Click to enlarge to full size]
- Zotero users browse the Web, discover citations and save them into their personal libraries.
- Each time a Zotero instance discover a citation, it would send the URL where we can find it to PingtheSemanticWeb.com.
- Note: the user should be aware of that functionality via an option into Zotero that would explains him what this feature it is all about, and to gives him the possibility to disable it.
- Note: Zotero would ping PTSW each time it detects a citation (so that the icon appears in the FireFox’s URL bar), and not each time a user save it.
- Via the Virtuoso Sponger, PingtheSemanticWeb.com will check the incoming URL from Zotero users and will check to find citations too. If a citation is found, it will be added to its list of know citations and archive their content.
- PingtheSemanticWeb.com will then send the new citations to Zitgist so that it can include them into its database.
- Note: here Zitgist could be replaced by any web service wanting them. Remember that PTSW act as a data-multiplexer.
- Via Zitgist (that is a semantic web search engine), users from around the World will be able to search among these citations (discovered by Zotero users) and to browse them.
Zitgist has a Zotero citation provider
What is fantastic here is that Zitgist become a source of citations. So if a Zitgist user has Zotero installed, then he will be able to batch-save the list of results returned by Zitgist; and if the user is browsing Zitgist’s citations, he will be able to include them into their Zotero instance like if Zitgist would be Amazon.com or any other citations web sites.
That way, Zotero’s found data would be accessible to Zotero users via Zitgist that would then become a citations provider (mainly feed by the Zotero community).
You see the interaction?
What have to be developed?
Some things have to be developed to make that vision working. No major development, but only a couple of features to develop on each system.
Integration of Ping the Semantic Web into Zotero
The integration of Ping the Semantic Web into Zotero is quite straightforward.
Pinging PingtheSemanticWeb.com via a web service
The first step is to make Zotero notify PTSW each time it comes across a citation. It has to send the URL of that/these citation(s) via XML-RPC or REST.
That is it. Each time Zotero detect a citation, it sends a simple ping to PTSW via an XML-RPC or REST request.
Adding a pinging option to Zotero
Another thing that Zotero would have to add to their add-on is an option that would gives the possibility to their users to disable that feature in case they don’t want to send a notification to PTSW each time they discover a citation on a Web page while they are browsing the Web.
Development of Zotero translators into Sponger Metadata Cartridge
The biggest development effort that would have to be done is to convert the Zotero translators into Virtuoso Sponger’s Metadata Cartridge.
Right now, Metadata Cartridge exists for: Google Base, Flickr, microformats (hReview, hCalendar, etc.), etc. These cartridges are the same things as “Zotero translators” but for the Virtuoso Sponger. By developing these cartridges, everybody running Virtuoso will be able to see these citations (from Amazon, etc.) as RDF data (mapped using some ontologies).
Documentation about how to develop these cartridges will be available in the coming days. From there, we would be able to setup an effort to convert the Zotero Translators into Spongers Metadata Cartridges.
Conclusion
This is the vision I have of the integration of Zotero into the current Semantic Web environment that exists. Any ideas, suggestions, collaboration propositions would be warmly welcome.
Note: a discussion about this subject started on Zotero’s web forum