I am pleased to announce the pre-release of the Zitgist RDF Browser. This new tool from Zitgist will help users to browse the information available on the Semantic Web. As you will see bellow, this tool is a sort of information shape-shifter. Depending on the data available for a given Thing (a resource), it will shapes its user interface so that the data is best displayed for a better understanding of its semantic and for a better browsing experience.
This pre-release version is usable by anybody, however I would appreciate that you report any bug, issues or suggestions to me so that I can enhance the browser to meet people’s expectations.
Introducing Zitgist’s RDF Browser
The Templating system
The core of this new RDF browser is its templating system. This system will enhance the RDF browsing experience of users along with their understand of the information displayed to them. People can see it as a typical web browser such as Internet Explorer or FireFox, but instead of reading and displaying HTML, it display RDF data. Users only have to put the URI of a resource (it can be a URL where the browser can find RDF information about this Thing), then pressing the “browse” button.
Then, depending on the information available about this Thing, the RDF browser will shape its interface to optimize users’ browsing experience with the data.
Sources of data
Data displayed in the Zitgist RDF Browser can come from many different data sources:
- Zitgist’s internal RDF datastore
- URI dereferencing
- On-the-fly conversation of data sources such as:
- Microformats
- RDFa
- eRDF
- HTML meta tags
- API data source such as: Amazon.com, Google Base, etc.
So, depending on what information is available for a given URI, the browser will mesh-up these data sources and displays the information to the user.
First example of the templating system
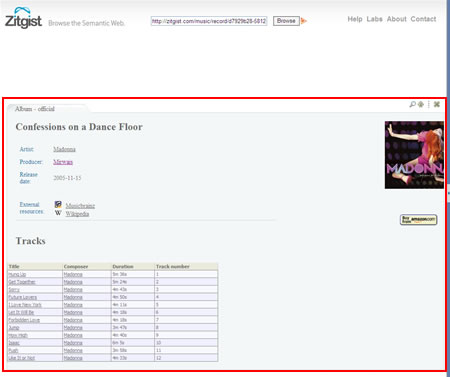
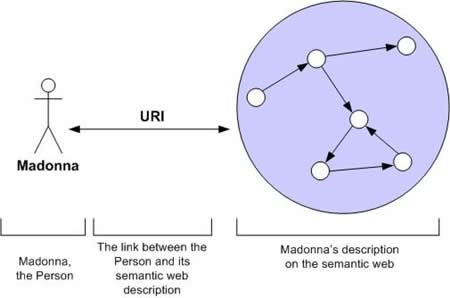
This first example shows how the browser will create a web page out of a RDF data source. In this case, the data source is a URI where Madonna’s latest album “Confession on a Dance Floor” is described.
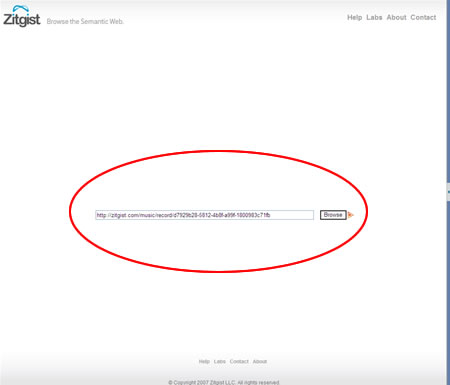
- The browser will check for that URI: http://zitgist.com/music/record/d7929b28-5812-4b8f-a99f-1800983c71fb
- No information is available in its data store, so it will dereference the URI to get the RDF triples describing the album.
- All in all, 15 different URIs will be dereferenced to create the web page.
- The browser will detect that the type of the entity related to this URI is a mo:Album; so it will triggers the “moAlbum” template to skin the data source so that the user can easily see and understand the information we have about this resource (music album).
- Then the skinned information is displayed to the user.
The templating system in action
Now we will see the templating system in action. In fact, the RDF browser does much more than skinning a single data source.
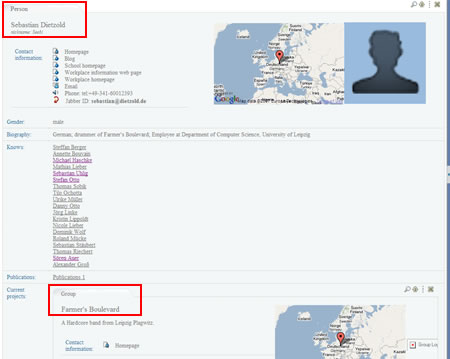
If you put that URI in the browser, you will see Sebastian’s profile. The browser will fire the foafPerson template, and his profile will be skinned according to this template.
However, what is interesting in that example is not only Sebastian’s profile, but the entities it links to. In fact, if you take a closer look and go down the page a little bit, you will notice the “Current projects” section of his profile. Then you will see a list of projects.
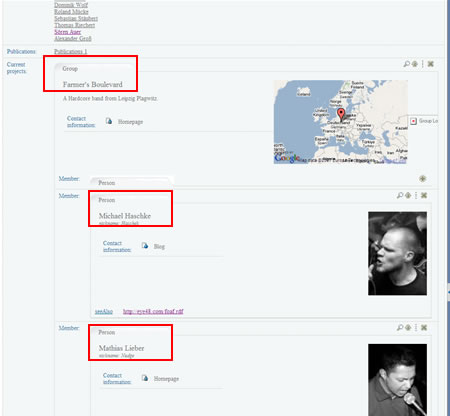
The first project is a musical group described as a foaf:Group. So, the browser will check the URI Sebastian’s profile link to, get information about it, skin it accordingly to the foafGroup template, and embed the result within Sebastian’s profile page.
Since we could embed such entities at infinitum, the browser restricts this automatic browsing to 3 deep levels in the graph.
Finally, we can “lookup” an individual embedded item by clicking on the lookup icon at the upper right corner of each entity.
Sidebar Navigator
In some cases some generated web page can be quite large, so a navigation widget has been developed to help users to navigate generated documents. The navigation of a document is based on the entities displayed in it.
For example, if we run the Zitgist RDF Browser for that URI: http://www.macosxhints.com, we will notice that information displayed is many pages long. So, to help us navigating this long document, we will use the entity navigator widget.
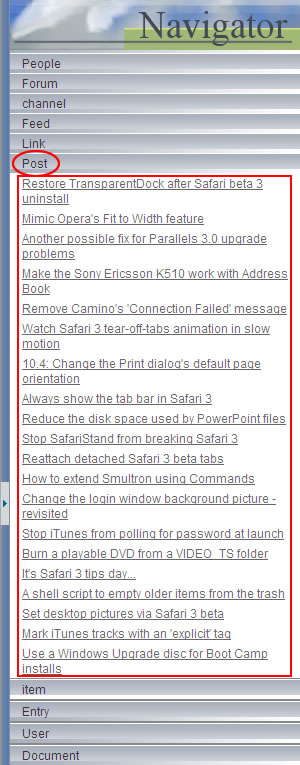
All the types available in that web page are listed in the sidebar, and for each type you have all the instances available.
In that example, you can easily browse the web feed of that web page. In a click, you can see all Posts, Feeds and Authors.
Interesting examples
There is a list of starting points to see the Zitgist RDF Browser in action:
- http://www.macosxhints.com/
- Browsing a web feed converted into RDF.
- http://swaml.berlios.de/doap.rdf
- The genetic template used to display the description of a doap:Project
- http://homepages.cwi.nl/~ivan/AboutMe/CV/publist.rdf
- Ivan Herman’s list of publications.
- http://b4mad.net/2006/05/30/googlegroups-sioc-dev.rdf
- Google group described using SIOC.
- http://iswc2004.semanticweb.org/posters/metadata.rdf
- Poster abstracts of the ISWC2004 conference.
- And all the examples above.
Bookmarklet
The Zitgist RDF Browser can process any URI. So, from any web page, a user can launch the browser to see what semantic web information is available for that URI. Then, all the information the browser can find/generate out of that data source will be displayed to the user.
To help users, I developed this really simple bookmarklet that get the URI of the current web page, send it to the browser, and then redirect the user to the browser’s generated page.
Zitgist RDF Browser’s Bookmarklet
Conclusion
As you noticed above, this new RDF browser is a sort of information shape-shifter. Depending on the information available for a given URI, it will skin it to make it easier to browse and understand for users.