| I am pleased to announce the first phase of the public release of the UMBEL Web Services by Zitgist. This first release consists of a series of user interfaces in-front of several UMBEL web services. |
 |
This blog post shows and explains what these web services are about and how people will be able to use them to leverage UMBEL to create new ontologies, to instantiate new data sets and to interlink external ontologies to explode their domains.
Background
For the last four to six months we have been in the process of creating the UMBEL ontology. We have been doing research to find the best basis datasets; we have been cleaning these datasets for UMBEL’s purposes; and we have been developing the ontology and its principles. Starting today, we begin the release process for UMBEL:
- UMBEL web services’ user interfaces
- UMBEL ontology (OWL-Full)
- UMBEL ontology technical documentation
- UMBEL subject concepts’ structure (SKOS + OWL-Full) & named entities instantiation
- UMBEL web services endpoints.
UMBEL Ontology & Subject Concept Structure
Before starting to show and explain the UMBEL web services’ user interfaces’, I have to give some background information about the UMBEL ontology’s principles, and how the subject concept structure has been created. All this information will be discussed and explained at length in the UMBEL ontology technical documentation that is about to be published; but I have to give some technical background information in order to explain what these web services are about.
As described by Mike, UMBEL’s purposes are:
“[…] to provide a lightweight structure of subject concepts as a reference to what Web content or data “is about”, what is called a concept schema in SKOS […]
Think of the backbone as a set of roadsigns to help find related content. UMBEL is like a map of an interstate highway system, a way of getting from one big place to another. Once in the right vicinity, other maps (or ontologies), more akin to detailed street maps, are then necessary to get to specific locations or street addresses.
By definition, these more fine-grained maps are beyond UMBEL’s scope. But UMBEL can help provide the context for placing such detailed maps in relation to one another and in relation to the Big Picture of what related content is about.
These subject concepts also provide the mapping points for the many, many thousands (indeed, millions) of specific named entities that are the notable instances of these subject concepts. Examples might include the names of specific physicists, cities in a country, or a listing of financial stock exchanges. UMBEL mappings enable us to link a given named entity to the various subject classes of which it is a member.
And, because of relationships amongst subject concepts in the backbone, we can also relate that entity to other related entities and concepts. The UMBEL backbone traces the major pathways through the content graph of the Web. For some visualizations of this subject graph, see So, What Might The Web’s Subject Backbone Look Like?”
A four-article introduction to UMBEL can be read from Mike’s blog at:
UMBEL is a 21 000 subject concept structure that has been derived from the OpenCyc ontology. The structure is described in SKOS and OWL-Full. Each concept is an invididual of the skos:Concept class, which are themselves OWL classes. This dichotomy is the basis of UMBEL. Since the subject concepts are classes, this mean that we can relate these classes to external ontology classes using properties such as rdfs:subClassOf and owl:equivalentClass.
So what does all of this mean? It means that once the linkages between UMBEL subject concepts and external ontologies classes are made, the following becomes possible: 1) the UMBEL subject concept structure can be used to describe (instantiate) things using the UMBEL data structure; 2) external ontology properties can be re-used to describe these new instances since external ontologies classes are linked to UMBEL subject concept classes; and 3) in some cases, the properties defined in these ontologies can be used in relation with UMBEL subject concept classes. The forthcoming technical documentation about this stuff will provide more detailed explanation. For the moment, just accept these assertions as being true.
The UMBEL web services (user interfaces) have been created to help people to manage these relationships between UMBEL subject concepts classes and external ontology classes. People will use the services to infer facts from the structure of the subject concepts, to check if a class is a sub-class, a super-class or an equivalent class of another class. They will also use the services to see what properties, defined in external ontologies, can be re-used, and on which subject concept.
Let the show begin!
UMBEL Web Services Index Page
The entry page lists all the available web services. For each web service, you have a link to the web service user interface, a link to an about page explaining the basis of the web service, and a link to the technical documentation of the web service endpoint: how to communicate with the endpoint web server and how to interpret the answer sent by the web service.
Take note that the web service endpoints are not yet publicly available, and that this endpoint page is provided now for information purposes.
Eleven UMBEL Web Services
- Find Subject Concepts
- Subject Concept Report
- Subject Concept Detailed Report
- List Sub-Concepts & Sub-Classes
- List Super-Concepts & Super-Classes
- List Equivalent External Classes
- Verify Sub-Class Relationship
- Verify Super-Class Relationship
- Verify Equivalent Class Relationship
- Subject Concepts Explorer
- Yago Ontology — a little help from our friends.
Searching the UMBEL Subject Concept Structure
The first thing people will want to do is to search within the UMBEL subject concept structure. The “Find Subject Concepts” web service helps people to locate potential subject concept they are looking for.
If someone looks at the Find Subject Concepts page and performs a search for the keyword “project”, he will get this list of subject concepts:
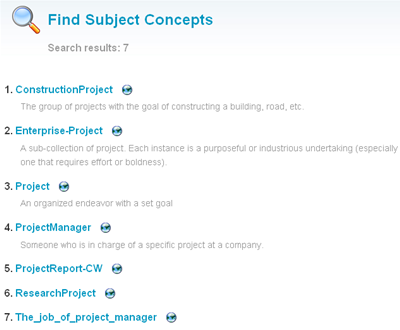
Note: all subject concepts are ordered alphabetically and the search has been performed on the subject concept label and their semsets (and not in their definition).
The “finding” web service along with all the inferencing web services use the same result page layout: you have a list of subject concepts with their human readable definition (note: 8000 definitions out of 21 000 have yet to be created). If a user clicks on a result, he will be redirected to the Report and the Detailed Report user interfaces. Additionally, a user can click on the small “earth” icon to start browsing the surrounding subject concepts nodes in the Explorer visualization tool.
Inferencing the UMBEL Subject Concept Structure
A series of web services has been created to infer facts in the UMBEL subject concept structure. There are the two main categories of inferencing web services:
- The ones that list subject concepts that are more general, more specific or equivalent to a given subject concept
- The ones that answer the question: is this subject concept a sub-concept, a super-concept or an equivalent concept to this other subject concept?
These web services can be used not only to infer these facts on UMBEL subject concepts, but also on external ontology classes. There are a couple of examples of what can be done with these inferencing web services:
Note: some people may notice that the doap:Project external ontology class is a sub-class of the “Project” subject concept. This is not intuitive for humans, but this situation will be explained at length in the UMBEL Ontology Technical Documentation. To make a long story short: considering the nature of the current definition of the doap:Project class, we couldn’t say that it is equivalent to the “Project” UMBEL subject concept.
Visualizing the UMBEL Subject Concept Structure
While inferencing and lookup are good, we still have some issues when we try to “feel” what the UMBEL subject concept structure is. The following two user interfaces will do their best to help people visualizing the subject concepts description and their relations with other subject concepts and external ontologies classes.
Lets start with a wonderful visualization tool, created by Moritz Stefaner, and used by UMBEL to let people visualizing and browsing the data structure.
Lets start by browsing the relationship of the “Project” subject concept:
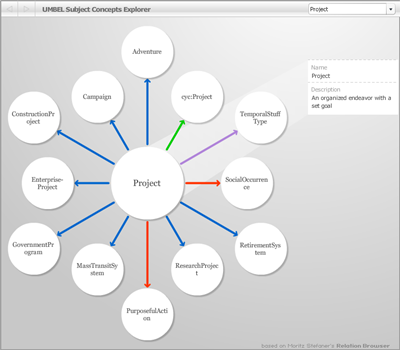
You can navigate from one node to another by clicking any of the circles. Each circle is an UMBEL subject concept or an external ontology class.
When a node is selected, its concept description is displayed in the right sidebar of the interface.
Note there are four different kinds of relationship between the concepts:
- Blue (B). (concept A) — broader than –> (Concept B). concept A is more general than concept B
- Red (N). (concept A) — narrower than –> (Concept B). concept A is more specific than concept B
- Green (=). (concept A) — equivalent to –> (Concept B). concept A is equivalent to concept B
- Mauve (I). (concept A) — is a –> (Concept B). concept A is an instance of the concept B
As each node is selected, the display refreshes and shows the new set of relationships for the current node (subject concept or external class). Note the dropdown list shown at the upper right of the display enables you to return to previous views or steps.
The Detailed Subject Concept Report
The detailed subject concept report is the tool to know everything about a specific subject concept. This is not really a web service, but a user interface that uses all existing UMBEL web services to display a detailed report of a subject concept, and all its relations with other UMBEL subject concepts and external ontology classes and properties.
There is the detailed report of the “Project” subject concept:

There is the list of information available from that detailed report page:
- UMBEL Subject Concept Name — the name of the subject concept
- Semset — the preferred label and its alternative labels used to refer to this concept. The alternative labels are aliases, synonyms, collocations, etc.; related to the preferred label of the subject concept
- Definition — the human readable definition of the subject concept
- Equivalent External Classes — the classes from external ontologies that refer to this same subject concept. Note that the UMBEL Ontology Technical Documentation will explain how the equivalence relation between an external ontology class and an UMBEL subject concept is done
- Named Entities — a list of named entities related to this UMBEL subject concept. Most of the time, the subject concept has the “type of” characteristic for these named entities. For example, for the subject concept “Person”, “Albert Einstein” is of type “Person”. The first named entities data set that has been used to create this list of named entities is Yago (more about this below).
- More General External Classes — these are the classes from external ontologies that refer to a more general concept. Note that the UMBEL Ontology Technical Documentation will explain how the super-class relation between an external ontology class and an UMBEL subject concept is done
- More Specific External Classes — these are the classes from external ontologies that refer to a more specific concept. Note that the UMBEL Ontology Technical Documentation will explain how the sub-class relation between an external ontology class and an UMBEL subject concept is done
- In-domain-of — this is a list of properties defined in external ontologies where an individual of the UMBEL subject concept class can be used in the domain of the property. For example, for the subject concept “Person” the in-domain-of property: “foaf:interest (domain: foaf:Person)” means that an individual of the class umbel:Project can re-use the property foaf:interest that is defined in the FOAF ontology in its domain (<umbel:Person> <foaf:internet> <…>). Note that the UMBEL Ontology Technical Documentation will explain how the in-domain-of relation between an external ontology class and an UMBEL subject concept is done
- In-range-of — this is a list of properties defined in external ontologies where an individual of the UMBEL subject concept class can be used in the range of the property. For example, for the subject concept “Person” the in-range-of property: “doap:developer (range: foaf:Person)” means that an individual of the class umbel:Project can re-use the property doap:developer that is defined in the DOAP ontology in its range (<…> <doap:developer> <umbel:Person>). Note that the UMBEL Ontology Technical Documentation will explain how the in-range-of relation between an external ontology class and an UMBEL subject concept is done
- More General Subject Concepts — this is the list of more general internal UMBEL subject concepts related to the concept
- More Specific Subject Concepts — this is the list of more specific internal UMBEL subject concepts related to the concept.
As you can notice, all the relations between any UMBEL subject concept to other subject concepts or external ontologies classes and properties is shown in this detailed report page.
This detailed report page was created not only to show people what UMBEL subject concepts are. I envision that people (more specifically ontologies developer & ontologies users) will also use it to check the current linkage between UMBEL and external ontologies and how to use UMBEL to instantiate and describe resources in RDF, etc. The UMBEL ontology documentation will describe some linkage and re-using use cases in further detail.
Linked External Ontologies and Named Entities
Lets take a deeper look at the named entities section of the detailed report of the “Person” subject concept:

These named entities are individuals belonging to the class umbel:Person. If you click on one of these person names, you will notice that they are described the Yago data set. How is this possible?
To make another long story short: umbel:Person is an equivalent class to the cyc:Person class; cyc:Person is an equivalent class to the wordnet:Person class; yago:R._B._Bennett is an individual belonging to the same wordnet:Person class. So we can infer that yago:R._B._Bennett is an individual also belonging to the umbel:Person class. However, these technical details will be explained at length in the UMBEL ontology documentation.
But the truth is that this is not the most wonderful thing around. The most wonderful thing is when we understand what that really means (the linkage between yago:R._B._Bennett and umbel:Person (or any other data sets linked to UMBEL)). This means that this linkage is literally exploding the domain of each of these linked named entities. In fact, now we know this about yago:R._B._Bennett:
- It is an umbel:Person
- It is a cyc:Person
- It is a foaf:Person & a foaf:Agent
- It is a umbel:HomoSapiens
- It is a umbel:SocialBeing
- That we can re-use the foaf:birthday, foaf:name, doap:translator, dcterms:creator, etc.; external ontologies properties to describe this person.
We can infer all these things, and much more, about yago:R._B._Bennett only by linking it to UMBEL. We just contextualized it; and then we exploded its domain!
This is what UMBEL is about; this is the value it creates; and its contribution to the Semantic Web.
Conclusion
This is just the beginning of UMBEL. Currently ten external ontologies have been linked to UMBEL. The attentive eye will notice some strange results in the in-domain-of and in-range-of detailed report sections. More work has to be put in the linkage; however as you will notice in the technical documentation of UMBEL, some weird results come from the way some ontologies are defined. So, these ontologies self-definition create some of these weird results. So this mean that these UMBEL tools won’t only help by linking external ontologies, but they will also help to define new ontologies and to fix existing ones.
Stay tuned; more stuff will be released in the coming weeks and months.








