I am pleased to announce the pre-release of the Zitgist RDF Browser. This new tool from Zitgist will help users to browse the information available on the Semantic Web. As you will see bellow, this tool is a sort of information shape-shifter. Depending on the data available for a given Thing (a resource), it will shapes its user interface so that the data is best displayed for a better understanding of its semantic and for a better browsing experience.
This pre-release version is usable by anybody, however I would appreciate that you report any bug, issues or suggestions to me so that I can enhance the browser to meet people’s expectations.
Introducing Zitgist’s RDF Browser
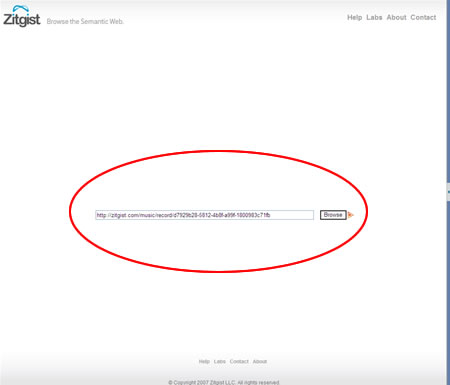
The Templating system
The core of this new RDF browser is its templating system. This system will enhance the RDF browsing experience of users along with their understand of the information displayed to them. People can see it as a typical web browser such as Internet Explorer or FireFox, but instead of reading and displaying HTML, it display RDF data. Users only have to put the URI of a resource (it can be a URL where the browser can find RDF information about this Thing), then pressing the “browse” button.
Then, depending on the information available about this Thing, the RDF browser will shape its interface to optimize users’ browsing experience with the data.
Sources of data
Data displayed in the Zitgist RDF Browser can come from many different data sources:
- Zitgist’s internal RDF datastore
- URI dereferencing
- On-the-fly conversation of data sources such as:
- Microformats
- RDFa
- eRDF
- HTML meta tags
- API data source such as: Amazon.com, Google Base, etc.
So, depending on what information is available for a given URI, the browser will mesh-up these data sources and displays the information to the user.
First example of the templating system
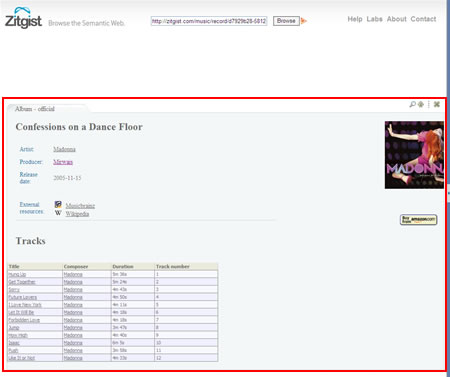
This first example shows how the browser will create a web page out of a RDF data source. In this case, the data source is a URI where Madonna’s latest album “Confession on a Dance Floor” is described.
- The browser will check for that URI: http://zitgist.com/music/record/d7929b28-5812-4b8f-a99f-1800983c71fb
- No information is available in its data store, so it will dereference the URI to get the RDF triples describing the album.
- All in all, 15 different URIs will be dereferenced to create the web page.
- The browser will detect that the type of the entity related to this URI is a mo:Album; so it will triggers the “moAlbum” template to skin the data source so that the user can easily see and understand the information we have about this resource (music album).
- Then the skinned information is displayed to the user.
The templating system in action
Now we will see the templating system in action. In fact, the RDF browser does much more than skinning a single data source.
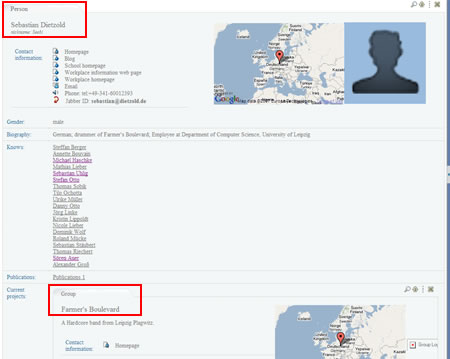
If you put that URI in the browser, you will see Sebastian’s profile. The browser will fire the foafPerson template, and his profile will be skinned according to this template.
However, what is interesting in that example is not only Sebastian’s profile, but the entities it links to. In fact, if you take a closer look and go down the page a little bit, you will notice the “Current projects” section of his profile. Then you will see a list of projects.
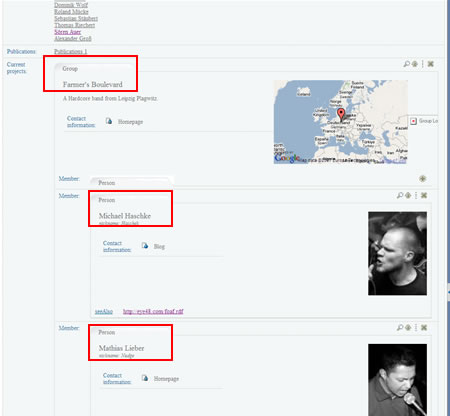
The first project is a musical group described as a foaf:Group. So, the browser will check the URI Sebastian’s profile link to, get information about it, skin it accordingly to the foafGroup template, and embed the result within Sebastian’s profile page.
Since we could embed such entities at infinitum, the browser restricts this automatic browsing to 3 deep levels in the graph.
Finally, we can “lookup” an individual embedded item by clicking on the lookup icon at the upper right corner of each entity.
Sidebar Navigator
In some cases some generated web page can be quite large, so a navigation widget has been developed to help users to navigate generated documents. The navigation of a document is based on the entities displayed in it.
For example, if we run the Zitgist RDF Browser for that URI: http://www.macosxhints.com, we will notice that information displayed is many pages long. So, to help us navigating this long document, we will use the entity navigator widget.
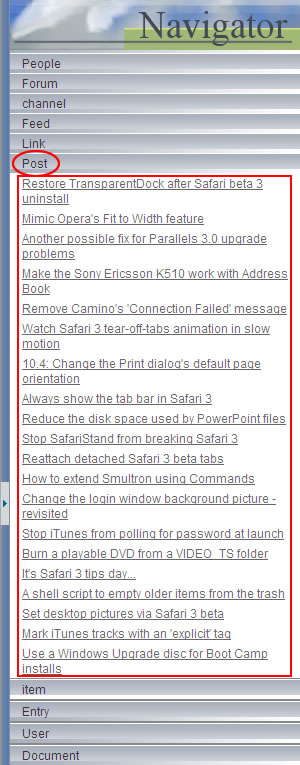
All the types available in that web page are listed in the sidebar, and for each type you have all the instances available.
In that example, you can easily browse the web feed of that web page. In a click, you can see all Posts, Feeds and Authors.
Interesting examples
There is a list of starting points to see the Zitgist RDF Browser in action:
- http://www.macosxhints.com/
- Browsing a web feed converted into RDF.
- http://swaml.berlios.de/doap.rdf
- The genetic template used to display the description of a doap:Project
- http://homepages.cwi.nl/~ivan/AboutMe/CV/publist.rdf
- Ivan Herman’s list of publications.
- http://b4mad.net/2006/05/30/googlegroups-sioc-dev.rdf
- Google group described using SIOC.
- http://iswc2004.semanticweb.org/posters/metadata.rdf
- Poster abstracts of the ISWC2004 conference.
- And all the examples above.
Bookmarklet
The Zitgist RDF Browser can process any URI. So, from any web page, a user can launch the browser to see what semantic web information is available for that URI. Then, all the information the browser can find/generate out of that data source will be displayed to the user.
To help users, I developed this really simple bookmarklet that get the URI of the current web page, send it to the browser, and then redirect the user to the browser’s generated page.
Zitgist RDF Browser’s Bookmarklet
Conclusion
As you noticed above, this new RDF browser is a sort of information shape-shifter. Depending on the information available for a given URI, it will skin it to make it easier to browse and understand for users.
J Hendler
June 20, 2007 — 1:20 pm
It looks like it could be an interesting thing to use – but every URI I’ve tried it on has failed — I keep getting the message that the RDF cannot be handled. I’ve tried it on several of your examples and also on my foaf file (http://www.cs.rpi.edu/~hendler/foaf.rdf” — I’ve sent these to the validator and they all validate – so I’m guessing it is something in the URIs being created – JH
Laurens Holst
June 21, 2007 — 3:02 am
I really like it! One issue I’ve always had with RDF browsers is that they don’t really represent the data in a user-friendly way.
Carl Eggeberg
June 21, 2007 — 7:00 am
Like
http://sites.wiwiss.fu-berlin.de/suhl/bizer/ng4j/disco/
but closed source?
I’d suggest you to get help by open sourcing it to gather more work and ideas , given that the problem has been faced many times and by quite skilled people and is recognized as being very hard (creating something that people generically can appreciate and want to work with that visualize RDF)
Carl
Mh
June 21, 2007 — 4:00 pm
Very nice, always a pleasure to see that hand-tailored n3 being nicely visualized.
Minor things I encountered so far (I can’t give details in a bug report it seems): email-adresses turn into “mailto:mailto:adress”; in the Navigator it would be nice if the header is collapsable, so you dont have to scroll down.
cheers,
M
Bruce D'Arcus
June 21, 2007 — 4:00 pm
Weird. I posted a question yesterday, but it seems not to be here. Question was: what’s the templating language? Fresnel?
Fred
June 21, 2007 — 7:13 pm
Hi all,
Mr. Handler: yeah, we experienced some issues with the server in the first hours, should be back to normal now.
Mr. Holst: Thanks for the kind words 🙂
Mr. Eggeberg: well, it is to consider, but it is not in Zitgist’s plans for the moment. In fact, it is much different than DISCO on many, many points. Also, it is not because it is closed source that it doesn’t generate ideas and community works. In fact, it is totally the opposite since everything it evolving with it is related to the semantic web (the ontologies it skins, ontology development, rdf views (mo), etc, etc, etc.).
MH: okay good, I will take a look at it tomorrow. Also, I will upgrade the bug report mechanism. In fact I wanted it as simple as possible, but it seems a little bit too simplistic 🙂
Bruce: A templating system of my own. However, I will eventually consider to make fresnel templates working for non existing local templates. However I am not set about this idea at the moment.
Take care all,
Salutations,
Fred
Ivan Herman
June 22, 2007 — 7:52 am
Hi Fred,
really nice stuff. As you used my list as an example, I felt obliged to try it right away:-) However, just like Jim, I had difficulties with the URI handling. When I typed in
http://www.bibsonomy.org/swrc/tag/sweo
it worked all right, but if I type in
http://www.bibsonomy.org/swrc/tag/sweo books?items=300
It reports an invalid site (though, as far as I can see, it *is* valid). Another disagreeable issue is that I cannot really edit the URI side: if I click on the text box, the whole content is wiped out, ie, I have to retype the URI again (using Firefox on WinXP).
Another issue, more on the specific template: I wonder whether you could order the entries in, say, a FOAF file. If my foaf file is displayed, then the first entry you see is, well, the entry and photo for Richard Cyganiak. Nothing against Richard… but I would expect to see my data first (yeah, I know, vanity rules:-)
But this is really good stuff!
Ivan
Fred
June 22, 2007 — 8:15 am
Hi Ivan,
Yeah, I just noticed that in the log, I will take a look at the problem this morning, but I can tell you that it is not a problem with the validity of the document, but to fetch it from the server. Probably a small issue easily resolvable 🙂 Retry this afternoon and it should be fixed.
Okay, next next issue: you at the top of the page 🙂 The issue here is a classic one because of the “#” relative URI nightmare. 🙂
In fact, you specified your URI without “#me” in it. So, what the browser do is displaying the related rdf document, classifying the entities by type (of “importance”) and then displaying them to the user. There is no way for the browser to know “who” is supposed to be at the top of this page. In fact, in the best of the world, only you should be defined at this URI, and the other people and resources of this document should have their own URI (not relative).
Personally, I think that for each URI there should only be one resource described. (opposed to one URI == one RDF document (which may contain many resources).
You see the issue here?
Take care,
Fred
Ivan Herman
June 22, 2007 — 8:47 am
I am not sure what you mean by one URI one resource…
But, indeed, if I display now the URI http://wwww.ivan-herman.net/foaf.rdf#me, I see myself on the top. But if I then click on, say, Lee’s foaf URI I see again others… Yes, it is a bit messy….
Fred
June 22, 2007 — 9:06 am
Hi Ivan,
Well, this is a problem I am talking from time to time with Kingsley.
The current issue I see with today’s semantic web, is that people think about URI as a place where to get a RDF document; and in that rdf document, there can be more than one resource described. In format definitions, its true and legal, etc. However, I am personally not satisfied with that.
We shouldn’t think about a URI as a RDF Document, but about a Resource. So, for each URI a single resource should be defined. Then, if you want to describe more than one resource, you create new URIs. If you want to make them accessible from the web (dereferencing) then you use HTTP and create resolvable URIs.
This issue is introduced by the use of “#” can permit the usage of relative URI references (inside a rdf document), that is bad according to my point above.
One of the worse thing I see is the definition of a URI using a foaf:Document; and its why I have some questions about DERI’s wya to do things (did you followed the discussion on the LInked Data mailing list?)
So, according to what you just experienced with the zitgist rdf browser, it is the reason why I finally come to this conclusion: one URI one resource; and that we shouldn’t see a URI as a rdf “document” but as a resource description rdf data source.
Is it clearer?
Take care,
Fred
Fred
June 22, 2007 — 9:48 am
Hi again Ivan,
Your issue with the bib URI is not fixed. So you can retry to browse them without (we hope) any issue 🙂
Take care,
Fred
Ivan Herman
June 24, 2007 — 6:14 am
Fred,
a different issue. I know (well, I presume…) you use Virtuoso as an underlying engine. Having played with it I know that it has a sophisticated, say, caching mechanism to store graphs locally whenever it is possible, to ensure speed. And that is fine, but… sometimes it may go wrong.
What happened is: I looked at my foaf file again and I realized that it display an old version… I have changed a few days ago the two links to the publications and you still display the old ones. Ie, I presume you used my foaf for earlier tests and it got stuck in the local triple store.
I know that is difficult to control. Maybe the best is to have a button on the screen for refresh which would force virtuoso to, well, refresh…
Cheers
Ivan
Fred
June 24, 2007 — 5:38 pm
Hi Ivan!
[quote post=”816″]What happened is: I looked at my foaf file again and I realized that it display an old version… I have changed a few days ago the two links to the publications and you still display the old ones. Ie, I presume you used my foaf for earlier tests and it got stuck in the local triple store.
[/quote]
I know you would notice it 🙂 In fact, there are many levels underlying the browser: Triple store (ptsw), sponging and other graphs. It is a problem for sure, however this problem will be fixed once the underlying architecture will be finished (it is what zitgist is).
I thought about your solution, and I will add it on Monday. Then, once everything will be complete under-the-hood, I’ll simply remove it since it will become useless.
So, by the end of Monday, you will be able to refresh each source. In fact, the real issue with your foaf is that it is a old version archived by ptsw months ago.
However this should be fixed later this week since I am working to enhance PTSW and the new version should be available by the end of the week.
Anyway, many things are going on, many things has to be done, and its the exact reason why I said that it was a pre-release 🙂
Take care,
Fred
Patrick Gosetti-Murrayjohn
June 26, 2007 — 10:14 am
Fred,
Thanks for the comment on my blog. I’m introducing the semantic web to some of the faculty I work with, and this all is helping greatly.
I did have one question–It looks like some of the links to DBpedia resources were dereferenced, and others not. Does zitgist treat objects of dc:subject and foaf:topic_interest differently?
I’m looking at my experimental connection to Memex at
http://devel.patrickgmj.net/dmcResources/testConnection.n3#e
and my foaf at
http://www.patrickgmj.net/foaf.rdf#me
And, your points about #s are well taken.
Thanks,
Patrick
Fred
June 27, 2007 — 3:09 pm
Hi Patrick!
Thanks for passing by.
What do you mean about DBPedia resources? Yeah, some of them are, others no, it really depends on the case. However, what did you noticed that could be wrong?
Thanks
take care,
Fred
Patrick Gosetti-Murrayjohn
June 28, 2007 — 9:21 am
Fred,
I think what you say that it depends on the case might explain it. In particular, in my foaf I have:
foaf:topic_interest <http://dbpedia.org/resource/XML>
Clicking that in the zitgist browser happily takes me to DBpedia info in the zitgist browser.
However, in another document (the one I link to in previous comment) I have:
dc:subject <http://dbpedia.org/resource/Memex>
Clicking that gives me the page that says zitgist doesn’t understand the document. When I tried this a few days ago, though, I was redirected to the DBpedia page http://dbpedia.org/page/Memex, which popped me out of the zitgist browser. (Might the difference between the result today and the result a few days ago be due to the proxy issue I saw Chris Bizer write about in the DBpedia discussion list today?)
So, in the experience a few days ago, in one case the DBpedia data came up in the zitgist browser, in another I was taken out of the browser right to the DBpedia page. If it’s a case by case thing, then that might be the expected result–just wanted to double check if whether it’s expected or a surprise.
Thanks much,
Patrick
Fred
June 28, 2007 — 9:55 am
Hi Patrick,
Yeah, and its easy to understand. Take a look at the DBpedia mailing list archive, Chris posted a discussion between Kingsley and TimBL about it. You are experiencing the same gateway problem:
http://dbpedia.org/resource/Memex
put that in your web browser, and you will see. The issue here is that the Zitgist Browser can’t access the file, so it can’t display anything. And since the data isn’t into its triple store, it can’t do anything about it.
But a couple of days ago, it was working because they changed something (something called Puppy) in their architecture.
Take care,
Fred
Laurent Saint Jean
July 15, 2007 — 8:14 am
Really excited to try out your new browser.
However, it seems the links provided aren’t loading for some reason.
Am i missing something ?
best.
Laurent
Fred
July 16, 2007 — 5:59 pm
Hi Laurent,
Yeah, the issue is that we are experiencing issues with the server where the browser software instance is installed. So it render it unfortunately useless.
I hope we will be able to fix the server soon (next days).
It is the beauty with pre-release web services 🙂 Down times are longer than usually.
So stay tuned.
Thanks,
Take care,
Fred
Badri
August 14, 2007 — 1:36 am
Fred,
I am curious to try it out too. Didn’t find it working just now (tried all the links in your page and some others too). Should I expect it to be up some time soon?
Regards,
Badri
Fred
August 15, 2007 — 9:19 am
Hi Badri,
Sorry for these issues, but the browser should be back up and running later today or tomorrow morning in the worse case.
Sorry about that 🙁
Take care,
Fred
Ramanathan S
September 4, 2008 — 6:53 am
Is this project closed? I have not seen any action on this from Aug 2007 – 1 year by now.
A revival or availability (or the new address if any) would be helpful for my research on Semantic Web.
Thanks for the understanding.
With warm regards
S Ramanathan (Ram)
Fred
September 4, 2008 — 1:20 pm
Hi Ramanthan,
No it is not; it just changed a bit 🙂
You can search this blog for “DataViewer” for more information about this project.
You can now access it here: http://dataviewer.zitgist.com
Happy browsing!
Take care,
Fred