In the first part of this series we found the good hyperparameters for a single linear SVM classifier. In part 2, we will try another technique to improve the performance of the system: ensemble learning.
So far, we already reached 95% of accuracy with some tweaking the hyperparameters and the training corpuses but the F1 score is still around ~70% with the full gold standard which can be improved. There are also situations when precision should be nearly perfect (because false positives are really not acceptable) or when the recall should be optimized.
Here we will try to improve this situation by using ensemble learning. It uses multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone. In our examples, each model will have a vote and the weight of the vote will be equal for each mode. We will use five different strategies to create the models that will belong to the ensemble:
- Bootstrap aggregating (bagging)
- Asymmetric bagging 1
- Random subspace method (feature bagging)
- Asymmetric bagging + random subspace method (ABRS) 1
- Bootstrap aggregating + random subspace method (BRS)
Different strategies will be used depending on different things like: are the positive and negative training documents unbalanced? How many features does the model have? etc. Let’s introduce each of these different strategies.
Note that in this article I am only creating ensembles with linear SVM learners. However an ensemble can be composed of multiple different kind of learners, like SVM with non-linear kernels, decisions trees, etc. However, to simplify this article, we will stick to a single linear SVM with multiple different training corpuses and features.
[extoc]
Ensemble Learning Strategies
Bootstrap Aggregating (bagging)
The idea behind bagging is to draw a subset of positive and negative training samples at random and with replacement. Each model of the ensemble will have a different training set but some of the training sample may appear in multiple different training sets.
Asymmetric Bagging
Asymmetric Bagging has been proposed by Tao, Tang, Li and Wu 1. The idea is to use asymmetric bagging when the number of positive training samples is largely unbalanced relatively to the negative training samples. The idea is to create a subset of random (with replacement) negative training samples, but by always keeping the full set of positive training samples.
Random Subspace method (feature bagging)
The idea behind feature bagging is the same as bagging, but works on the features of the model instead of the training sets. It attempts to reduce the correlation between estimators (features) in an ensemble by training them on random samples of features instead of the entire feature set.
Asymmetric Bagging + Random Subspace method (ABRS)
Asymmetric Bagging and Random Subspace Method has also been proposed by Tao, Tang, Li and Wu 1. The problems they had with their content-based image retrieval system are the same we have with this kind of automatic training corpuses generated from knowledge graph:
- SVM is unstable on small-sized training set
- SVM’s optimal hyperplane may be biased when the positive training sample is much less than the negative feedback sample (this is why we used weights in this case), and
- The training set is smaller than the number of features in the SVM model.
The third point is not immediately an issue for us (except if you have a domain with many more features than we had in our example), but becomes one when we start using asymmetric bagging.
What we want to do here is to implement asymmetric bagging and the random subspace method to create ![]() number of individual models. This method is called ABRS-SVM which stands for Asymmetric Bagging Random Subspace Support Vector Machines.
number of individual models. This method is called ABRS-SVM which stands for Asymmetric Bagging Random Subspace Support Vector Machines.
The algorithm we will use is:
- Let the number of positive training documents be
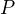 , the number of negative training document beÂ
, the number of negative training document be 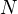 and the number of features in the training data be
and the number of features in the training data be 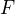 .
. - ChooseÂ
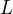 to be the number of individual models in the ensemble.
to be the number of individual models in the ensemble. - For all individual model
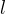 , chooseÂ
, choose 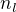 whereÂ
where 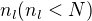 to be the number of negative training documents forÂ
to be the number of negative training documents for 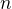
- For all individual models , chooseÂ
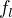 whereÂ
where 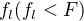 to be the number of input variables for
to be the number of input variables for 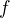 .
. - For each individual model , create a training set by choosing features from with replacement, by choosing negative training documents from with replacement, by choosing all positive training documents and then train the model.
Bootstrap Aggregating + Random Subspace method (BRS)
Bagging with features bagging is the same as asymmetric bagging with the random subspace method except that we use bagging instead of asymmetric bagging. (ABRS should be used if your positive training sample is severely unbalanced compared to your negative training sample. Otherwise BRS should be used.)
SVM Learner
We use the linear Semantic Vector Machine (SVM) as the learner to use for the ensemble. What we will be creating is a series of SVM models that will be different depending on the ensemble method(s) we will use to create the ensemble.
Build Training Document Vectors
The first step we have to do is to create a structure where all the positive and negative training documents will have their vector representation. Since this is the task that takes the most time in the whole process, we will calculate them using the (build-svm-model-vectors) function and we will serialize the structure on the file system. That way, to create the ensemble’s models, we will only have to load it from the file system without having the re-calculate it each time.
Train, Classify and Evaluate Ensembles
The goal is to create a set of X number of SVM classifiers where each of them use different models. The models can differ in their features or their training corpus. Then each of the classifier will try to classify an input text according to their own model. Finally each classifier will vote to determine if that input text belong, or not, to the domain.
There are four hyperparameters related to ensemble learning:
- The mode to use
- The number of models we want to create in the ensemble
- The number of training documents we want in the training corpus, and
- The number of features.
Other hyperparameters could include the ones of the linear SVM classifier, but in this example we will simply reuse the best parameters we found above. We now train the ensemble using the (train-ensemble-svm) function.
Once the ensemble is created and trained, then we have to use the (classify-ensemble-text) function to classify an input text using the ensemble we created. That function takes two parameters: :mode, which is the ensemble’s mode, and :vote-acceptance-ratio, which defines the number of positive votes that is required such that the ensemble positively classify the input text. By default, the ratio is 50%, but if you want to optimize the precision of the ensemble, then you may want to increase that ratio to 70% or even 95% as we will see below.
Finally the ensemble, configured with all its hyperparameters, will be evaluated using the (evaluate-ensemble) function, which is the same as the (evaluate-model) function, but which uses the ensemble instead of a single SVM model to classify all of the articles. As before, we will characterize the assignments in relation to the gold standard.
Let’s now train different ensembles to try to improve the performance of the system.
Asymmetric Bagging
The current corpus training set is highly unbalanced. This is why the first test we will do is to apply the asymmetric bagging strategy. What this does is that each of the SVM classifiers will use the same positive training set with the same number of positive documents. However, each of them will take a random number of negative training documents (with replacement).
(use 'cognonto-esa.core) (use 'cognonto-esa.ensemble-svm) (load-dictionaries "resources/general-corpus-dictionary.pruned.csv" "resources/domain-corpus-dictionary.pruned.csv") (load-semantic-interpreter "base-pruned" "resources/semantic-interpreters/base-pruned/") (reset! ensemble []) (train-ensemble-svm "ensemble.base.pruned.ab.c2.w30" "resources/ensemble-svm/base-pruned/" :mode :ab :weight {1 30.0} :c 2 :e 0.001 :nb-models 100 :nb-training-documents 3500)
Now let’s evaluate this ensemble with a vote acceptance ratio of 50%
(evaluate-ensemble "ensemble.base.pruned.ab.c2.w30" "resources/gold-standard-full.csv" :mode :ab :vote-acceptance-ratio 0.50)
True positive: 48 False positive: 6 True negative: 917 False negative: 46 Precision: 0.8888889 Recall: 0.5106383 Accuracy: 0.9488692 F1: 0.6486486
Let’s increase the vote acceptance ratio to 90%:
(evaluate-ensemble "ensemble.base.pruned.ab.c2.w30" "resources/gold-standard-full.csv" :mode :ab :vote-acceptance-ratio 0.90)
True positive: 37 False positive: 2 True negative: 921 False negative: 57 Precision: 0.94871795 Recall: 0.39361703 Accuracy: 0.94198626 F1: 0.556391
In both cases, the precision increases considerably compared to the non-ensemble learning results. However, the recall did drop at the same time, which dropped the F1 score as well. Let’s now try with the ABRS method
Asymmetric Bagging + Random Subspace method (ABRS)
The goal of the random subspace method is to select a random set of features. This means that each model will have their own feature set and will make predictions according to them. With the ABRS strategy, we will conclude with highly different models since none will have the same negative training sets nor the same features.
Here what we test is to define each classifier with 65 randomly chosen features out of 174 to restrict the negative training corpus to 3500 randomly selected documents. Then we choose to create 300 models to try to get a really heterogeneous population of models.
(reset! ensemble []) (train-ensemble-svm "ensemble.base.pruned.abrs.c2.w30" "resources/ensemble-svm/base-pruned/" :mode :abrs :weight {1 30.0} :c 2 :e 0.001 :nb-models 300 :nb-features 65 :nb-training-documents 3500)
(evaluate-ensemble "ensemble.base.pruned.abrs.c2.w30" "resources/gold-standard-full.csv" :mode :abrs :vote-acceptance-ratio 0.50)
True positive: 41 False positive: 3 True negative: 920 False negative: 53 Precision: 0.9318182 Recall: 0.43617022 Accuracy: 0.9449361 F1: 0.59420294
For these features and training sets, using the ABRS method did not improve on the AB method we tried above.
Conclusion
This use case shows three totally different ways to use the KBpedia Knowledge Graph to automatically create positive and negative training sets. We demonstrated how the full process can be automated where the only requirement is to get a list of seed KBpedia reference concepts.
We also quantified the impact of using new versions of KBpedia, and how different strategies, techniques or algorithms can have different impacts on the prediction models.
Creating prediction models using supervised machine learning algorithms (which is currently the bulk of the learners currently used) has two global steps:
- Label training sets and generate gold standards, and
- Test, compare, and optimize different learners, ensembles and hyperparameters.
Unfortunately, today, given the manual efforts required by the first step, the overwhelming portion of time and budget is spent here to create a prediction model. By automating much of this process, Cognonto and KBpedia substantially reduces this effort. Time and budget can now be re-directed to the second step of “dialing in” the learners, where the real payoff occurs. of training corpuses.
Further, as we also demonstrated, once we automated this process of labeling and reference standards, then we can also automate the testing and optimization of multiple different kind of prediction algorithms, hyperparameters configuration, etc. In short, for both steps, KBpedia provides significant reductions in times and efforts to get to desired results.