word2vec is a two layer artificial neural network used to process text to learn relationships between words within a text corpus to create a model of all the relationships between the words of that corpus. The text corpus that a word2vec process uses to learn the relationships between words is called the training corpus.
In this article I will show you how Cognonto‘s knowledge base can be used to automatically create highly accurate domain specific training corpuses that can be used by word2vec to generate word relationship models. However you have to understand that what is being discussed here is not only applicable to word2vec, but to any method that uses corpuses of text for training. For example, in another article, I will show how this can be done with another algorithm called ESA (Explicit Semantic Analysis).
It is said about word2vec that “given enough data, usage and contexts, word2vec can make highly accurate guesses about a word’s meaning based on past appearances.” What I will show in this article is how to determine the context and we will see how this impacts the results.
Training Corpus
A training corpus is really just a set of text used to train unsupervised machine learning algorithms. Any kind of text can be used by word2vec. The only thing it does is to learn the relationships between the words that exist in the text. However, not all training corpuses are equal. Training corpuses are often dirty, biaised and ambiguous. Depending on the task at hand, it may be exactly what is required, but more often than not, their errors need to be fixed. Cognonto has the advantage of starting with clean text.
When we want to create a new training corpus, the first step is to find a source of text that could work to create that corpus. The second step is to select the text we want to add to it. The third step is to pre-process that corpus of text to perform different operations on the text, such as: removing HTML elements; removing punctuation; normalizing text; detecting named entities; etc. The final step is to train word2vec to generate the model.
word2vec is somewhat dumb. It only learns what exists in the training corpus. It does not do anything other than “reading” the text and analyzing the relationships between the words (which are really just group of characters separated by spaces). The word2vec process is highly subject to the Garbage In, Garbage Out principle, which means that if the training set is dirty, biaised and ambiguous, then the learned relationship will end-up being of little or no value.
Domain-specific Training Corpus
A domain-specific training corpus is a specialized training corpus where its text is related to a specific domain. Examples of domains are music, mathematics, cars, healthcare, etc. In contrast, a general training corpus is a corpus of text that may contain text that discusses totally different domains. By creating a corpus of text that covers a specific domain of interest, we limit the usage of words (that is, their co-occurrences) to texts that are meaningful to that domain.
As we will see in this article, a domain-specific training corpus can be quite useful, and much more powerful, than general ones, if the task at hand is in relation to a specific domain of expertise. The major problem with domain-specific training corpuses is that they are really costly to create. We not only have to find the source of data to use, but we also have to select each document that we want to include in the training corpus. This can work if we want a corpus with 100 or 200 documents, but what if you want a training corpus of 100,000 or 200,000 documents? Then it becomes a problem.
It is the kind of problem that Cognonto helps to resolve. Cognonto and KBpedia, its knowledge base, is a set of ~39,000 reference concepts that have ~138,000 links to schema of external data sources such as Wikipedia, Wikidata and USPTO. It is that structure and these links to external data sources that we use to create domain-specific training corpuses on the fly. We leverage the reference concept structure to select all of the concepts that should be part of the domain that is being defined. Then we use Cognonto’s inference capabilities to infer all the other hundred or thousands of concepts that define the full scope of the domain. Then we analyze the hundreds or thousands of concepts we selected that way to get all of the links to external data sources. Finally we use these references to create the training corpus. All of this is done automatically once the initial few concepts that define my domain got selected. The workflow looks like:
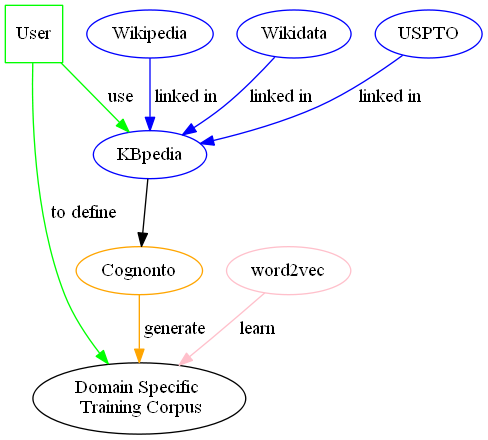
The Process
To show you how this process works, I will create a domain-specific training set about musicians using Cognonto. Then I will use the Google News word2vec model created by Google and that has about 100 billion words. The Google model contains 300-dimensional vectors for 3 million words and phrases. I will use the Google News model as the general model to compare the results/performance between a domain specific and a general model.
Determining the Domain
The first step is to define the scope of the domain we want to create. For this article, I want a domain that is somewhat constrained to create a training corpus that is not too large for demo purposes. The domain I have chosen is musicians. This domain is related to people and bands that play music. It is also related to musical genres, instruments, music industry, etc.
To create my domain, I select a single KBpedia reference concept: Musician. If I wanted to broaden the scope of the domain, I could have included other concepts such as: Music, Musical Group, Musical Instrument, etc.
Aggregating the Domain-specific Training Corpus
Once we have determined the scope of the domain, the next step is to query the KBpedia knowledge base to aggregate all of the text that will belong to that training corpus. The end result of this operation is to create a training corpus with text that is only related to the scope of the domain we defined.
(defn create-domain-specific-training-set [target-kbpedia-class corpus-file] (let [step 1000 entities-dataset "http://kbpedia.org/knowledge-base/" kbpedia-dataset "http://kbpedia.org/kko/" nb-entities (get-nb-entities-for-class-ws target-kbpedia-class entities-dataset kbpedia-dataset)] (loop [nb 0 nb-processed 1] (when (< nb nb-entities) (doseq [entity (get-entities-slice target-kbpedia-class entities-dataset kbpedia-dataset :limit step :offset @nb-processed)] (spit corpus-file (str (get-entity-content entity) "\n") :append true) (println (str nb-processed "/" nb-entities))) (recur (+ nb step) (inc nb-processed)))))) (create-domain-specific-training-set "http://kbpedia.org/kko/rc/Musician" "resources/musicians-corpus.txt")
What this code does is to query the KBpedia knowledge base to get all the named entities that are linked to it, for the scope of the domain we defined. Then the text related to each entity is appended to a text file where each line is the text of a single entity.
Given the scope of the current demo, the musicians training corpus is composed of 47,263 documents. This is the crux of the demo. With a simple function, we are able to aggregate 47,263 text documents highly related to a conceptual domain we defined on the fly. All of the hard work has been delegated to the knowledge base and its conceptual structure (in fact, this simple function leverages 8 years of hard work).
Normalizing Text
The next step is a natural step related to any NLP pipeline. Before learning from the training corpus, we should clean and normalize the text of its raw form.
(defn normalize-proper-name [name] (-> name (string/replace #" " "_") (string/lower-case))) (defn pre-process-line [line] (-> (let [line (-> line ;; 1. remove all underscores (string/replace "_" " "))] ;; 2. detect named entities and change them with their underscore form, like: Fred Giasson -> fred_giasson (loop [entities (into [] (re-seq #"[\p{Lu}]([\p{Ll}]+|\.)(?:\s+[\p{Lu}]([\p{Ll}]+|\.))*(?:\s+[\p{Ll}][\p{Ll}\-]{1,3}){0,1}\s+[\p{Lu}]([\p{Ll}]+|\.)" line)) line line] (if (empty? entities) line (let [entity (first (first entities))] (recur (rest entities) (string/replace line entity (normalize-proper-name entity))))))) (string/replace (re-pattern stop-list) " ") ;; 4. remove everything between brackets like: [1] [edit] [show] (string/replace #"\[.*\]" " ") ;; 5. punctuation characters except the dot and the single quote, replace by nothing: (),[]-={}/\~!?%$@&*+:;<> (string/replace #"[\^\(\)\,\[\]\=\{\}\/\\\~\!\?\%\$\@\&\*\+:\;\<\>\"\p{Pd}]" " ") ;; 6. remove all numbers (string/replace #"[0-9]" " ") ;; 7. remove all words with 2 characters or less (string/replace #"\b[\p{L}]{0,2}\b" " ") ;; 10. normalize spaces (string/replace #"\s{2,}" " ") ;; 11. normalize dots with spaces (string/replace #"\s\." ".") ;; 12. normalize dots (string/replace #"\.{1,}" ".") ;; 13. normalize underscores (string/replace #"\_{1,}" "_") ;; 14. remove standalone single quotes (string/replace " ' " " ") ;; 15. re-normalize spaces (string/replace #"\s{2,}" " ") ;; 16. put everything lowercase (string/lower-case) (str "\n"))) (defn pre-process-corpus [in-file out-file] (spit out-file "" :append true) (with-open [file (clojure.java.io/reader in-file)] (doseq [line (line-seq file)] (spit out-file (pre-process-line line) :append true)))) (pre-process-corpus "resources/musicians-corpus.txt" "resources/musicians-corpus.clean.txt")
We remove all of the characters that may cause issues to the tokenizer used by the word2vec implementation. We also remove unnecessary words and other words that appear too often or that add nothing to the model we want to generate (like the listing of days and months). We also drop all numbers.
Training word2vec
The last step is to train word2vec on our clean domain-specific training corpus to generate the model we will use. For this demo, I will use the DL4J (Deep Learning for Java) library that is a Java implementation of the word2vec algorithm. Training word2vec is as simple as using the DL4J API like this:
(defn train [training-set-file model-file] (let [sentence-iterator (new LineSentenceIterator (clojure.java.io/file training-set-file)) tokenizer (new DefaultTokenizerFactory) vec (.. (new Word2Vec$Builder) (minWordFrequency 1) (windowSize 5) (layerSize 100) (iterate sentence-iterator) (tokenizerFactory tokenizer) build)] (.fit vec) (SerializationUtils/saveObject vec (io/file model-file)) vec)) (def musicians-model (train "resources/musicians-corpus.clean.txt" "resources/musicians-corpus.model"))
What is important to notice here is the number of parameters that can be defined to train word2vec on a corpus. In fact, that algorithm can be sensitive to parametrization.
Importing the General Model
The goal of this demo is to demonstrate the difference between a domain-specific model and a general model. Remember that the general model we chose was the Google News model that is composed of billion of words, but which is highly general. DL4J can import that model without having to generate it ourselves (in fact, only the model is distributed by Google, not the training corpus):
(defn import-google-news-model [] (org.deeplearning4j.models.embeddings.loader.WordVectorSerializer/loadGoogleModel (clojure.java.io/file "GoogleNews-vectors-negative300.bin.gz") true)) (def google-news-model (import-google-news-model))
Playing With Models
Now that we have a domain-specific model related to musicians and a general model related to news processed by Google, let’s start playing with both to see how they perform on different tasks. In the following examples, we will always compare the domain-specific training corpus with the general one.
Ambiguous Words
A characteristic of words is that their surface form can be ambiguous; they can have multiple meanings. An ambiguous word can co-occur with multiple other words that may not have any shared meaning. But all of this depends on the context. If we are in a general context, then this situation will happen more often than we think and will impact the similarity score of these ambiguous terms. However, as we will see, this phenomenum is greatly diminished when we use domain-specific models.
Similarity Between Piano, Organ and Violin
What we want to check is the relationship between 3 different music instruments: piano, organ and violin. We want to check the relationship between each of them.
(.similarity musicians-model "piano" "violin")
0.8422856330871582
(.similarity musicians-model "piano" "organ")
0.8573281764984131
As we can see, both tuples have a high likelihood of co-occurrence. This suggests that these terms of each tuple are probably highly related. In this case, it is probably because violins are often played along with a piano. And, it is probably that an organ looks like a piano (at least it has a keyboard).
Now let’s take a look at what the general model has to say about that:
(.similarity google-news-model "piano" "violin")
0.8228187561035156
(.similarity google-news-model "piano" "organ")
0.46168726682662964
The surprising fact here is the apparent dissimilarity between piano and organ compared with the results we got with the musicians domain-specific model. If we think a bit about this use case, we will probably conclude that these results makes sense. In fact, organ is an ambiguous word in a general context. An organ can be a musical instrument, but it can also be a part of an anatomy. This means that the word organ will co-occur beside piano, but also all kind of other words related to human and animal biology. This is why they are less similar in the general model than in the domain one, because it is an ambiguous word in a general context.
Similarity Between Album and Track
Now let’s see another similarity example between two other words album and track where track is an ambiguous word depending on the context.
(.similarity musicians-model "album" "track")
0.7943775653839111
(.similarity google-news-model "album" "track")
0.18461623787879944
As expected, because track is ambiguous, there is a big difference in terms of co-occurence probabilities depending on the context (domain-specific or general).
Similarity Between Pianist and Violinist
However, are domain-specific and general differences always the case? Let’s take a look at two words that are domain specific and unambiguous: pianist and violinist.
(.similarity musicians-model "pianist" "violinist")
0.8430571556091309
(.similarity google-news-model "pianist" "violinist")
0.8616064190864563
In this case, the similarity score between the two terms is almost the same. In both contexts (generals and domain specific), their co-occurrence is similar.
Nearest Words
Now let’s look at the similarity between two distinct words in two new and distinct contexts. Let’s take a look at a few words and see what other words occur most often with them.
Music
(.wordsNearest musicians-model ["music"] [] 7)
| music | revol samoilovich bunin | musical | amalgamating | assam. | voice | dance. |
(.wordsNearest google-news-model ["music"] [] 8)
| music | classical music | jazz | Music | Without Donny Kirshner | songs | musicians | tunes |
One observation we can make is that the terms from the musicians model are more general than the ones from the general model.
Track
(.wordsNearest musicians-model ["track"] [] 10)
| track | released. | album | latest | entitled | released | debut | year. | titled | positive |
(.wordsNearest google-news-model ["track"] [] 5)
| track | tracks | Track | racetrack | horseshoe shaped section |
As we know, track is ambiguous. The difference between these two sets of nearest related words is striking. There is a clear conceptual correlation in the musicians’ domain-specific model. But in the general model, it is really going in all directions.
Year
Now let’s take a look at a really general word: year
(.wordsNearest musicians-model ["year"] [] 11)
| year | ghantous. | he was grammy | naacap | grammy award for best | luces del alma | year. | grammy award | grammy for best | sitorai sol | nominated |
(.wordsNearest google-news-model ["year"] [] 10)
| year | month | week | months | decade | years | summer | year.The | September | weeks |
This one is quite interesting too. Both groups of words makes sense, but only in their respective contexts. With the musicians’ model, year is mostly related to awards (like the Grammy Awards 2016), categories like “song of the year”, etc.
In the context of the general model, year is really related to time concepts: months, seasons, etc.
Playing With Co-Occurrences Vectors
Finally we will play with manipulating the co-occurrences vectors by manipulating them. A really popular word2vec equation is king - man + women = queen. What is happening under the hood with this equation is that we are adding and substracting the co-occurences vectors for each of these words, and we check the nearest word of the resulting co-occurence vector.
Now, let’s take a look at a few of these equations.
Pianist + Renowned = ?
(.wordsNearest musicians-model ["pianist" "renowned"] [] 9)
| pianist | renowned | teacher. | composer. | prolific | virtuoso | teacher | leading | educator. |
(.wordsNearest google-news-model ["pianist" "renowned"] [] 7)
| renowned | pianist | pianist composer | jazz pianist | classical pianists | composer pianist | virtuoso pianist |
These kind of operations are kind of interesting. If we add the two co-occurrence vectors for pianist and renowned then we get that a teacher, an educator, a composer or a virtuoso is a renowned pianist.
For unambiguous surface forms like pianist, then the two models score quite well. The difference between the two examples comes from the way the general training corpus has been created (pre-processed) compared to the musicians corpus.
Metal + Death = ?
(.wordsNearest musicians-model ["metal" "death"] [] 10)
| metal | death | thrash | deathcore | melodic | doom | grindcore | metalcore | mathcore | heavy |
(.wordsNearest google-news-model ["metal" "death"] [] 5)
| death | metal | Tunstallbled | steel | Death |
This example uses two quite general words with no apparent relationship between them. The results with the musicians’ model are all the highly similar genre of music like trash metal, deathcore metal, etc.
However with the general model, it is a mix of multiple unrelated concepts.
Metal – Death + Smooth = ?
Let’s play some more with these equations. What if we want some kind of smooth metal?
(.wordsNearest musicians-model ["metal" "smooth"] ["death"] 5)
| smooth | fusion | funk | hard | neo |
This one is quite interesting. We substracted the death co-occurrence vector to the metal one, and then we added the smooth vector. What we end-up with is a bunch of music genres that are much smoother than death metal.
(.wordsNearest google-news-model ["metal" "smooth"] ["death"] 5)
| smooth | metal | Brushed aluminum | durable polycarbonate | chromed steel |
In the case of the general model, we end-up with “smooth metal”. The removal of the death vector has no effect on the results, probably since these are three ambiguous and really general terms.
What Is Next
The demo I presented in this article uses public datasets currently linked to KBpedia. You may wonder what are the other possibilities? Another possibility is to link your own private datasets to KBpedia. That way, these private datasets would then become usable, exactly in the same way, to create domain-specific training corpuses on the fly. Another possibility would be to take totally unstructured text like local text documents, or semi-structured text like a set of HTML web pages. Then, tag them using the Cognonto topics analyzer to tag each of the text document using KBpedia reference concepts. Then we could use the KBpedia structure exactly the same way to choose which of these documents we want to include in the domain-specific training corpus.
Conclusion
As we saw, creating domain-specific training corpuses to use with word2vec can have a dramatic impact on the results and how results can be much more meaningful within the scope of that domain. Another advantage of the domain-specific training corpuses is that they create much smaller models. This is quite an interesting characteristic since smaller models means they are faster to generate, faster to download/upload, faster to query, consumes less memory, etc.
Of the concepts in KBpedia, roughly 33,000 of them correspond to types (or classes) of various sorts. These pre-determined slices are available across all needs and domains to generate such domain-specific corpuses. Further, KBpedia is designed for rapid incorporation of your own domain information to add further to this discriminatory power.
Muhammad Javed
December 4, 2017 — 2:09 am
Hi, I want to generate domain specific corpus for training word2vec. kindly let me know how can I execute the code you mentioned in this article.
John Cramer
December 6, 2017 — 5:55 am
Interesting in theory. In practice this only works, since “musician” has a lot of entries. If you look for other concepts, there are generally just a couple of entries and most of them without any meaningful text, which means this method doesn’t work anymore.
Currently Kbpedia is definitely not ready to use in real word use cases, and due to the fact that half of the links for a concept seem broken (try “air pollution”) I doubt it will in the future.