I am giving a talk (in French) at the 85th edition of the ACFAS congress, May 9. I will discuss the engineering aspects of doing machine learning. But more importantly, I will discuss how Semantic Web techniques, technologies and specifications can help solving the engineering problems and how they can be leveraged and integrated in a machine learning workflow.
The focus of my talk is based on my work in the field of the semantic web in the last 15 years and my more recent work creating the KBpedia Knowledge Graph at Cognonto and how they influenced our work to develop different machine learning solutions to integrate data, to extend knowledge structure, to tag and disambiguate concepts and entities in corpuses of texts, etc.
One thing we experienced is that most of the work involved in such project is not directly related to machine learning problems (or at least related to the usage of machine learning algorithms). And then I recently read a survey conducted by CrowdFlower in 2016 that support what we experienced. They surveyed about 80 data scientists to probe them to find out “where they feel their profession is going, [and] what their day-to-day job is like” To the question: “What data scientists spend the most time doing”, they answered:
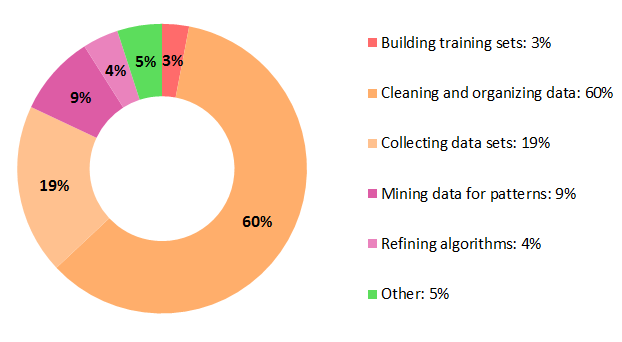
As you can notice, 77% percent of the time spent by a data scientist is related to non-machine learning algorithms selection, testing and refinement. If you read the survey, you will see that at the same time about 93% of the respondent said that these are the least enjoyable tasks! Which is a bit depressing… But on the other hand, we don’t know how much they disliked these tasks.
What I find interesting in the survey is that most of these non-machine learning algorithms specific tasks (again, 77% of them!) are data manipulation tasks that need to be engineered in some process/workflow/pipeline.
To put these numbers into context, I created my own general machine learning workflow schema. This is the one I used multiple times in the last few years while working on different projects for Cognonto. Depending on the task at hand, some step may differ and be added, but the core is there. Also note that all the tasks where this machine learning workflow has been used are related to natural language processing, entities matching, concepts and entities tagging and disambiguation. (click on it to access a bigger version of the schema)
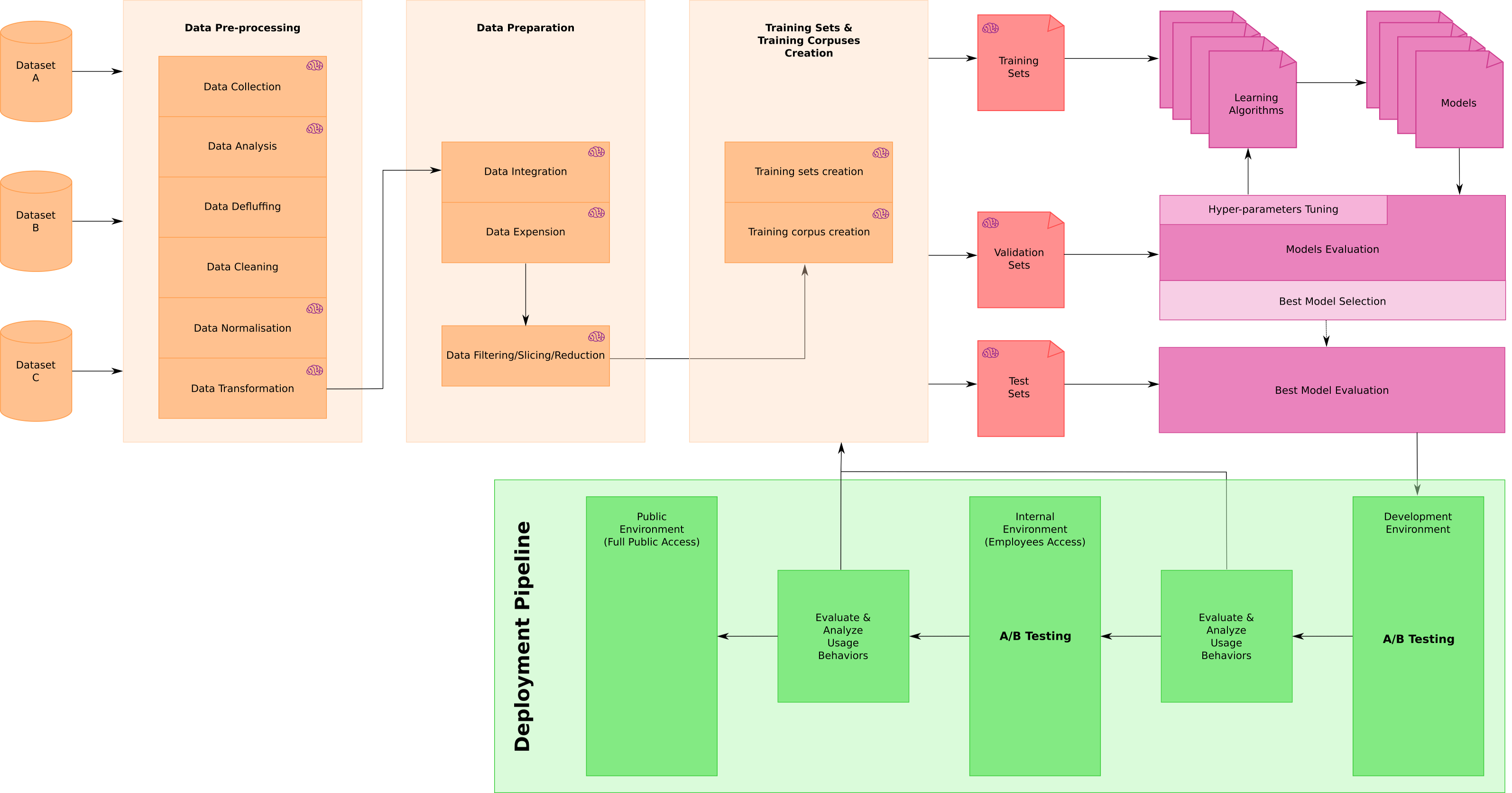
This workflow is split into four general areas:
- Data Processing
- Training Sets creation
- Machine Learning Algorithms testing, evaluation and selection
- Deployment and A/B testing
The only “real” machine learning work happens in the top-right corner of this schema and incurs only about 13% of the time spent by the data scientists according to the survey. All other tasks are related to data acquisition, data analysis, data normalization, data transformation, and then data integration, data filtering/slicing/reduction with which we will create a series of different training sets or training corpuses that will then lead to the creation (after proper splitting) of the training, validation and test sets.
It is only at that point that the data scientists will start testing algorithms to create different models, to evaluate them and to fine-tune the hyper-parameters. Once the best model(s) are selected, then we gradually put them into production with different steps of A/B testing.
Again, 77% of these tasks are related to non-machine learning algorithms tasks. These tasks are more related to an engineered pipeline which includes and ETL and an A/B testing frameworks. There is nothing sexy in this reality, but if data scientists spent 3/4 of their time working on these tasks then it suggests that they are highly important!
Note that every task with a small purple brain on it would benefit from leveraging a Knowledge Graph structure such as Cognonto’s KBpedia Knowledge Graph.