Today, I continue my investigation of how I can better leverage tools such as GitHub Copilot, and their impact on the work of software developers. I recently investigated how such tools can benefit from Literate Programming methodology.
I this new post, I am investigating the importance of carefully naming of functions, parameters and variables, and the impact on the performance of the tool.
Naming Things
More than 20 years ago, David Thomas and Andrew Hunt wrote in The Pragmatic Programmer:
The beginning of wisdom is to call things by their proper name.
— Confucius
What’s in a name? When we’re programming, the answer is “everything!”
We create names for applications, subsystems, modules, functions, variables — we’re constantly creating new things and bestowing names on them. And those names are very, very important, because they reveal a lot about your intent and belief.
We believe that things should be named according to the role they play in your code. This means that, whenever you create something, you need to pause and think “what is my motivation to create this?”
This is a powerful question, because it takes you out of the immediate problem-solving mindset and makes you look at the bigger picture. When you consider the role of a variable or function, you’re thinking about what is special about it, about what it can do, and what it interacts with. Often, we find ourselves realizing that what we were about to do made no sense, all because we couldn’t come up with an appropriate name.
Naming has always been a very hard and important problem in computer science, and this reality won’t change any time soon, if anything, it will get even more important in the coming new era composed of LLMs and Copilot like systems and tools.
The current premise we live with since roughly last Christmas, is that software developers productivity will experience a major boost helped by the new type of tooling that is becoming available, namely GitHub Copilot and its integration in VS Code. If the premise is true, and I have no indication at the time of this writing that it won’t, then the next immediate question become: how can we best use those tools to get the most pleasant and effective productivity boost?
Today, I am investigating the aspect of naming.
Meaningful vs. Meaningless
For this investigation, I will implement the exercise #10 of chapter 5.0.0 of The Art of Computer Programming:
10. [15] You are given a tape containing one million words of data. How do you determine how many distinct words are present open the tape?
The implementation will be in Python that will only require a handful of functions. This goes against the intent of the exercise, but I was lacking imagination to find something to code for this post.
For this experimentation, I created two empty and distinct workspaces. I loaded each of the workspace in different VS Code instances. The purpose here is to make sure that Copilot didn’t get any hint from elsewhere in the Workspace about my intents.
Then, I purposely didn’t write any comments, any text of any kind other than pure, uncommented, Python code. The rough structure of the implementation is:
- Use a book from the Gutenberg project as the source of token. In this case, we will use Marcel Proust’s translation of John Ruskin’s La Bible D’Amiens
- Tokenize the book in words
- Create a set of distinct words/tokens
Hopefully Meaningful Naming
For the first iteration, I tried to come up with hopefully more meaningful name for the functions and their parameters. The first step is to get a book from the Gutenberg project.
First thing I did is to start by typing the function name def get_project_guttenberg (notice the typo to Gutenberg).
The initial suggestion is not that helpful. It returns a string. But the function’s name is not that meaningful either. What does that mean? Am I looking for a project description for some kind of “Gutenberg project”?

Then I continued to type with def get_project_guttenberg_book That time, Copilot started to guess that I wanted to read a text book file from the file system. In reality, I am intending to simply download it directly from the web and not from the local file system. But we can see that it is heading in the right direction.

Then, I started to type the parameters of the function I was about to create def get_project_guttenberg_book(url. When I specify that the function is expecting a URL as input, it “understood” (really guessing at this point) that I want to get the book’s text from the web, so it suggested the following code:

def get_project_guttenberg_book(url: str) -> str:
"""Returns the text of a project guttenberg book"""
return requests.get(url).textThis is working, and the function’s design is working since the intent is clear even if we can fetch any Web document using that function (and not just Gutenberg project text books). We can always refine that function later when necessary.
But what if I would have used a different parameter’s name, let’s try this: def get_project_gutenberg_book(ebook_id:

By simply changing the parameter’s name by a more meaningful one creates a more specialized and purposeful function:
def get_project_gutenberg_book(ebook_id: str) -> str:
"""Returns the text of a project gutenberg book"""
return requests.get(f"https://www.gutenberg.org/cache/epub/{ebook_id}/pg{ebook_id}.txt").textNext step is to create the “data tape” from that source of text. Starting by typing def data_tape_ we can see that Copilot grasp the general intent of what we are trying to do even if it is not there yet.

If we tweak the function’s name a little bit with def get_data_tape_from_book(url then we are getting a more contextualized suggestion from Copilot. It is way too specific and probably hallucinating a little bit the structure of a Gutenberg book from its training set.

We will keep that suggestion and shorten the split() call to:
def get_data_tape_from_book(url: str) -> list:
"""Returns the data tape from a project guttenberg book"""
return get_project_guttenberg_book(url).split()The last step is to get the set of distinct words (from which we can calculate its len()). By starting typing def distinct_words_from_tape we are getting an adequate solution:

The tape is a list, it returns a set, a set of composed of distinct tokens. Simple and effective leverage of Python’s data structure.
def distinct_words_from_tape(tape: list) -> set:
"""Returns the distinct words from a data tape"""
return set(tape)We are done, the following gives us the number we are looking for:
len(distinct_words_from_tape(get_data_tape_from_book("https://www.gutenberg.org/cache/epub/62615/pg62615.txt")))Less Meaningful Naming
Now, see what happens when I use less meaningful names, when my brain becomes sloppier. def get_data(d gives us:
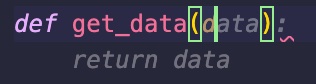
Not really what we are looking for, but this is understandable since there is zero context. Let’s continue with our initial idea by writing: def get_data(d): return requests. Now it is guessing that the d parameter is some data structure from which it can find the URL for the requests. And then it guesses that the request will read some json file that will need to be parsed. Most likely just because when people use the word data, they refer to some kind of structured data, and most likely that the most widely semi-structured data format out there exchanged over the web is still JSON. This is just what the Copilot learned from millions of Python projects.

If we continue typing def get_data(d): return requests.get(d) then it “thinks” that it will return some arrays where a URL will be accessible. At that time, it is just starting to hallucinate a solution.

I end-up simply writing that naive function without using any of the Copilot suggestions:
def get_data(d):
return requests.get(d).textNow that we have put the ground for some context with the get_data()function, let’s see how it goes to write the get_tape function. After typing def get_rape( I got:
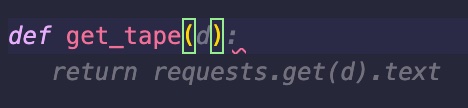
It just got it from the code I produced in get_data(). If I continue typing to change the parameter def get_tape(t), I get:
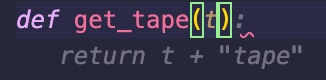
Not much more helpful. Let’s continue to type the body of the function: def get_tape(t): return get_data(t).spl it will finally propose to split on \n. But in reality, this is unnecessary and too narrow because when the first parameter of the split() function is None then the following happens:
When set to None (the default value), will split on any whitespace character (including \n \r \t \f and spaces) and will discard empty strings from the result.

The end result is that I didn’t use any suggestion to write get_tape():
def get_tape(t):
return get_data(t).split()Finally, we want to get the distinct words from the data tape. Start writing def distinct it almost propose the right thing. However, there is no reason to convert the set to a list before returning it:
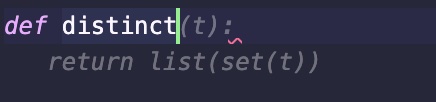
I ended up not using any suggestion for this function either:
def distinct(t):
return set(t)Conclusion
As we saw with those two examples, the proper naming of things is very important to get the most of this new kind of tooling. I agree that the second example is extreme, but in my experience they are not uncommon names that we can find in code bases. I didn’t try to obfuscate every name, the names where just too generals and a bit useless.
When David and Andrew wrote twenty years ago:
those names are very, very important, because they reveal a lot about your intent and belief
They considered those names very very important such that your intent and belief could be properly communicated to whoever read your code in the future (including you a few months from then). Today, this assertion stands true, but its scope is broader. Names are very, very important, because they also instruct assistant tools such as GitHub Copilot to more easily guess your intent and belief to help you write better code faster.
What I personally like with this new family of tools such as GitHub Copilot is how I think they will shape the software developers of tomorrow, how it will force them to be more careful about their writing, and in this case their naming. The better the writing, the most precise and unambiguous it is, the more power they will be able to harness from those LLMs.
I start to envision that the general productivity of software developers will experience an important boost in the coming five to ten years, but also (and more importantly to me) an overall increase in the quality of the code and systems they produce. All this because the tool became a huge incentive for them to care about those mundane non-code details such as writing mundane humans words.
Today, I feel that a lot of developers wonder if their job is at sake. In my next post, I will start outline what I am currently feeling around those questions. I don’t think developers job are at sake, but the way they work will definitely have to change, and the way we train future generations of software developers will have to change as well.