Since the beginning of the year, the industry’s main focus seems to revolve around “prompting.” We’ve seen the emergence of new job titles, new job descriptions, and even the introduction of “prompting wizards,” all of which are essentially part of branding and marketing strategies.
Prompting involves articulating a problem and providing clear instructions in the hope that the person or system reading it will produce the intended outcome. The recent shift lies in the recipient of these instructions: rather than a person taking action to solve the problem and follow the instructions, it’s now a thing (currently some form of AI model) that carries out the task.
What I find amusing, after 20 years of professional experience in software development and engineering management, is that we’re finally getting engineers to generate a substantial amount of text instead of solely focusing on writing code. This appears to signify quite a significant paradigm shift to me.
Prompting and Literate Programming
I recently had something of an epiphany while investigating the current state of Literate Programming: could Literate Programming not become a powerful software development paradigm with the advent of LLMs?
I mean, for 39 years, literate programming programmers have been essentially doing just this: “prompting” their software development. They have been describing their problems and outlining instructions before implementing the actual code, often in the format of a book or notebook. The only difference is that they were the ones doing 100% of the coding afterward (either themselves or with the help of an implementation development team).
Intuitively, it seems that this same format and these same skills are precisely what’s needed to best leverage LLMs in coding computer software. LLMs will undoubtedly become very effective tools, but they are just that: tools that need to be learned, experimented with, and mastered to extract the best results from them.
GitHub’s Copilot
In this blog post, I aim to explore how literate programming can influence and enhance the utilization of LLMs. The current leading LLM tool for software developers is undoubtedly GitHub’s Copilot, integrated into VS Code. It boasts three main features:
- Code completion
- Completions Panel (providing up to 10 distinct auto-completion suggestions)
- Chat (recently made available to the general public)
With all of these capabilities integrated into an IDE like VS Code, it forms a package that significantly accelerates the software development process.
The next question arises: will Copilot grasp, and potentially benefit from, the literate programming process in the suggestions it provides? This is what I’m aiming to explore – to observe how it reacts, what proves effective, and what may not.
To put it to the test, I’ve developed a straightforward command-line tool in Python designed to function as a basic calculator. The remainder of this post comprises a series of screenshots accompanied by my comments at each step.
literate-copilot
Before diving in, Is still needed to create a new GitHub project, and to use nbdev_new to create a new nbdev project, and then to configure it.
Before starting to develop the CLI tool, I wanted to see if GitHub Copilot was self aware of its own capabilities:
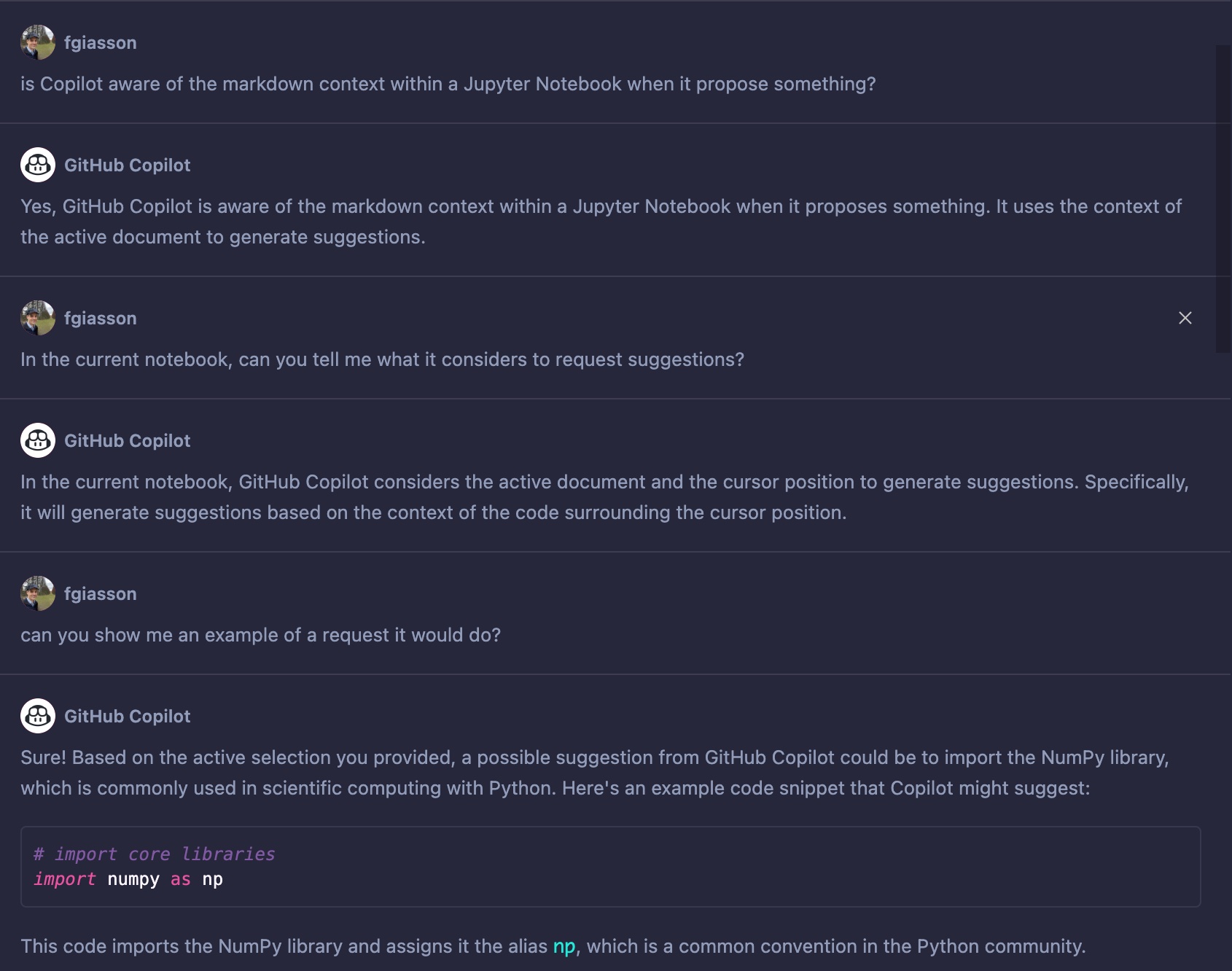
It’s hard to discern from this interaction whether it’s generating content or not, but at the very least, it seems promising. Let’s see if we can further explore this level of contextual awareness.
The initial step I took was to compose the introduction for the tool, right here in this Jupyter notebook. It outlines the purpose of the tool and the extensive list of calculator operations we aim to implement. I obtained the imports from the prior interaction with Chat. I manually added typer as this is the library I intend to use for building the command-line utility.
Following that, I proceeded to discuss creating a Typer application and its functionalities, etc. In the subsequent code block, I deliberately refrained from writing anything, as I didn’t want Copilot to auto-generate code within this block. I was interested in evaluating if it had an understanding of the entire notebook’s context, not just within a specific code block. This is why I opened the Suggestions Panel to assess if it would suggest anything relevant given the current context.
What I received was particularly interesting, as the initial suggestion aligns perfectly with the next step. It overlooks the #| export nbdev instruction, but that’s perfectly acceptable, as it’s rather obscure.
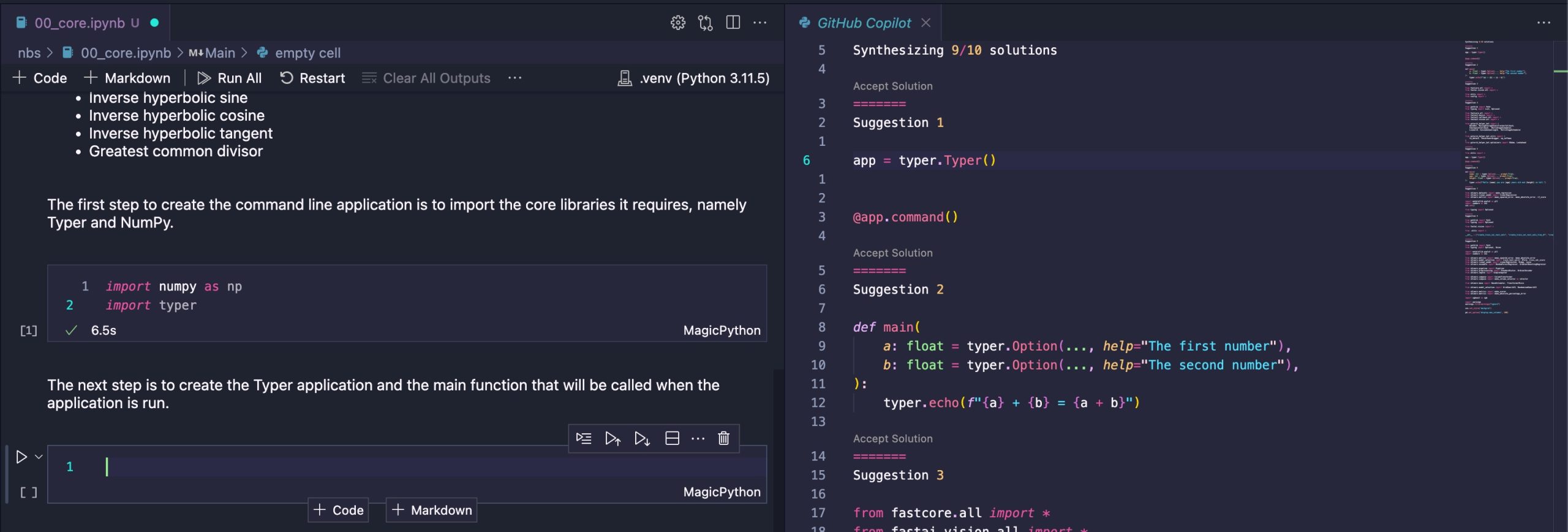
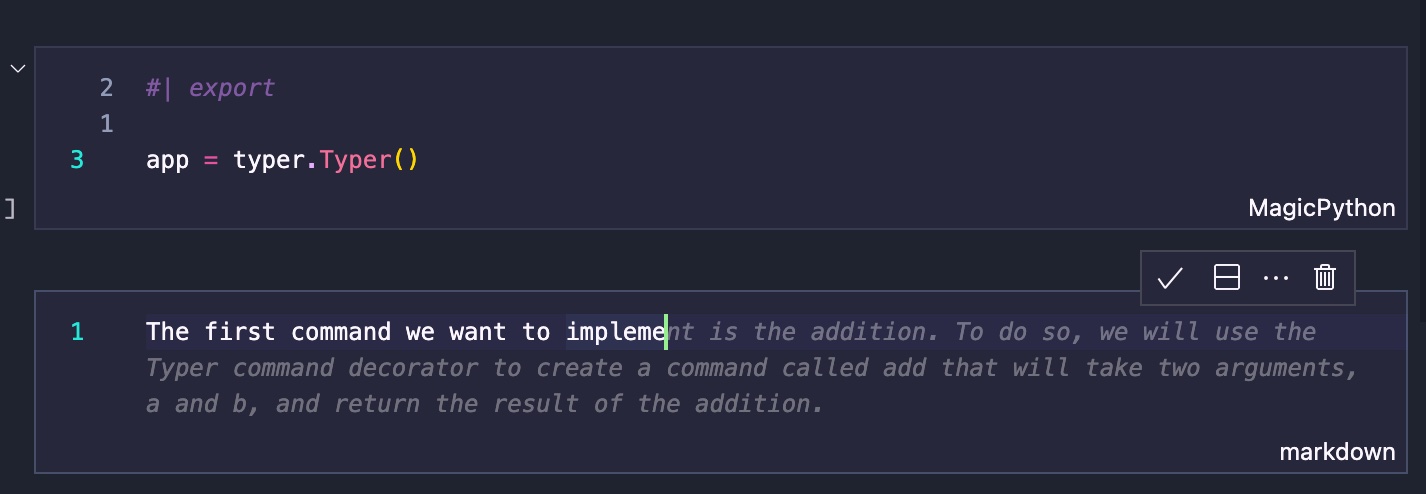
Next, I began detailing the subsequent steps by creating a new Markdown cell. At this point, Copilot’s auto-completion capabilities come into play. This is particularly interesting, as it essentially anticipates what I was about to write, drawing from the extensive list of calculator commands I plan to implement. In this case, it starts with the first command on that list, which is addition. This suggests to me that it leverages the entire notebook as the context for its suggestions.
For context, here is the full list of operations we want to implement:

However, this was actually not the first command we wanted to implement. The first one we wanted to implement is the version of the command line tool that we display to the users if they ask for it.
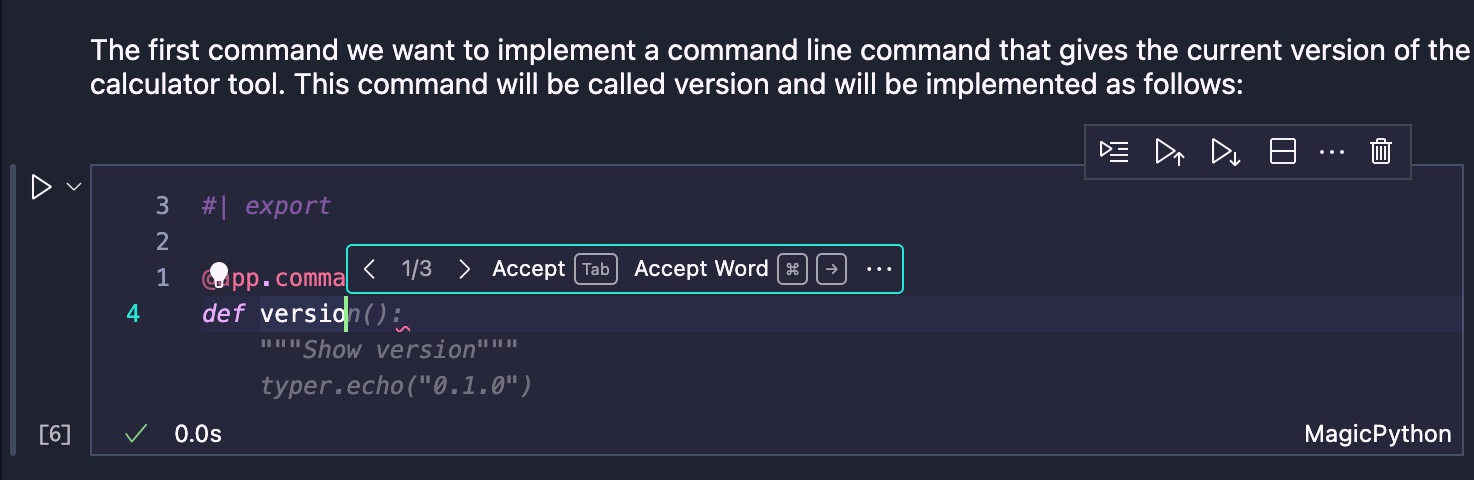
Then the next step is to start implementing the long list of calculator operations, starting with addition:
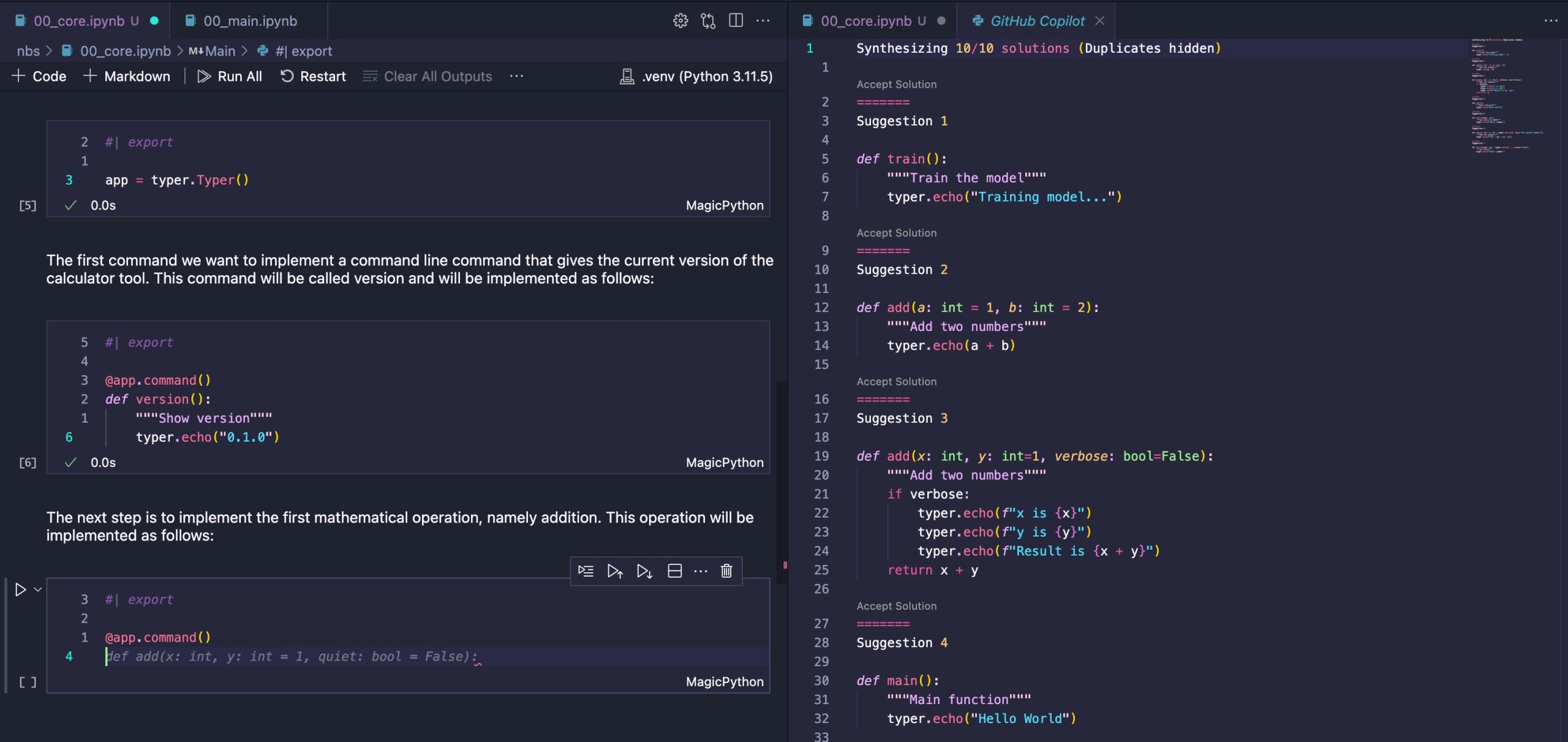
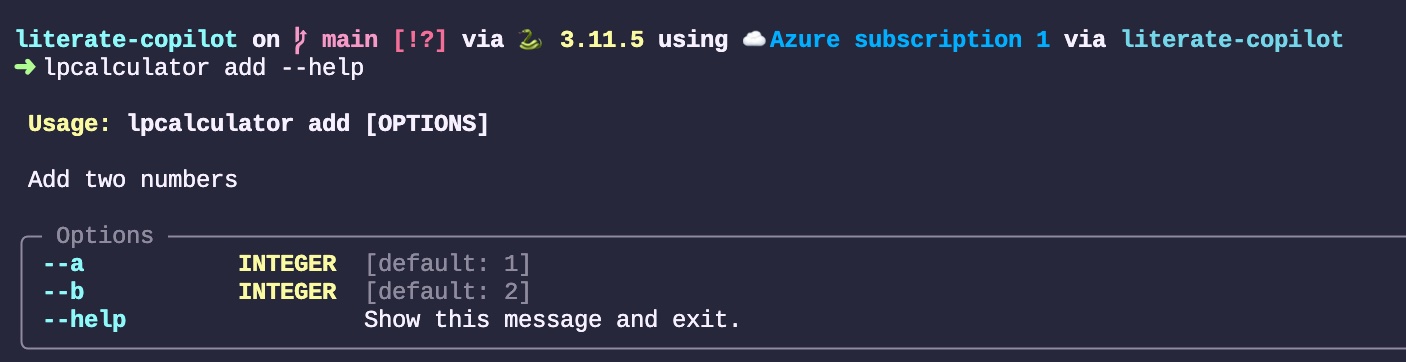
Why was the quiet parameter suggested? To dig a bit further into its thought process, I decided to open the Completions Panel. Suggestion 3 sheds light on what it had in mind. However, for a basic calculator, this isn’t very useful since the outcome of adding two numbers is quite straightforward. I’ll go ahead and accept .
Now, let’s compile this command-line application to ensure it functions as intended:
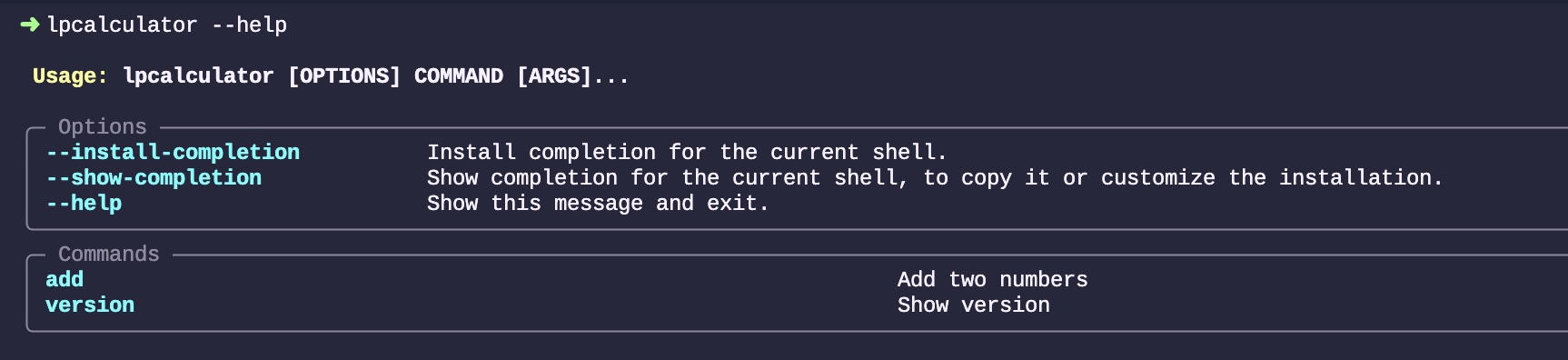
By blindly accepting the code proposed by Copilot, here is how the add command works:
Let’s see if it works as intended:

Yes, it does. It’s not the most convenient method for adding two numbers; it’s a bit complex and verbose, but it will suffice for now.
Afterwards, I added the entire list of operators in the same manner, by appending code block after code block, and it successfully implemented each of them. There was a point around number 7 or 8 where it lost the order, but simply starting to type the right term got it back on track. For example, typing def si will continue with defining the Sin function accordingly. Here is the current list that has been implemented so far:
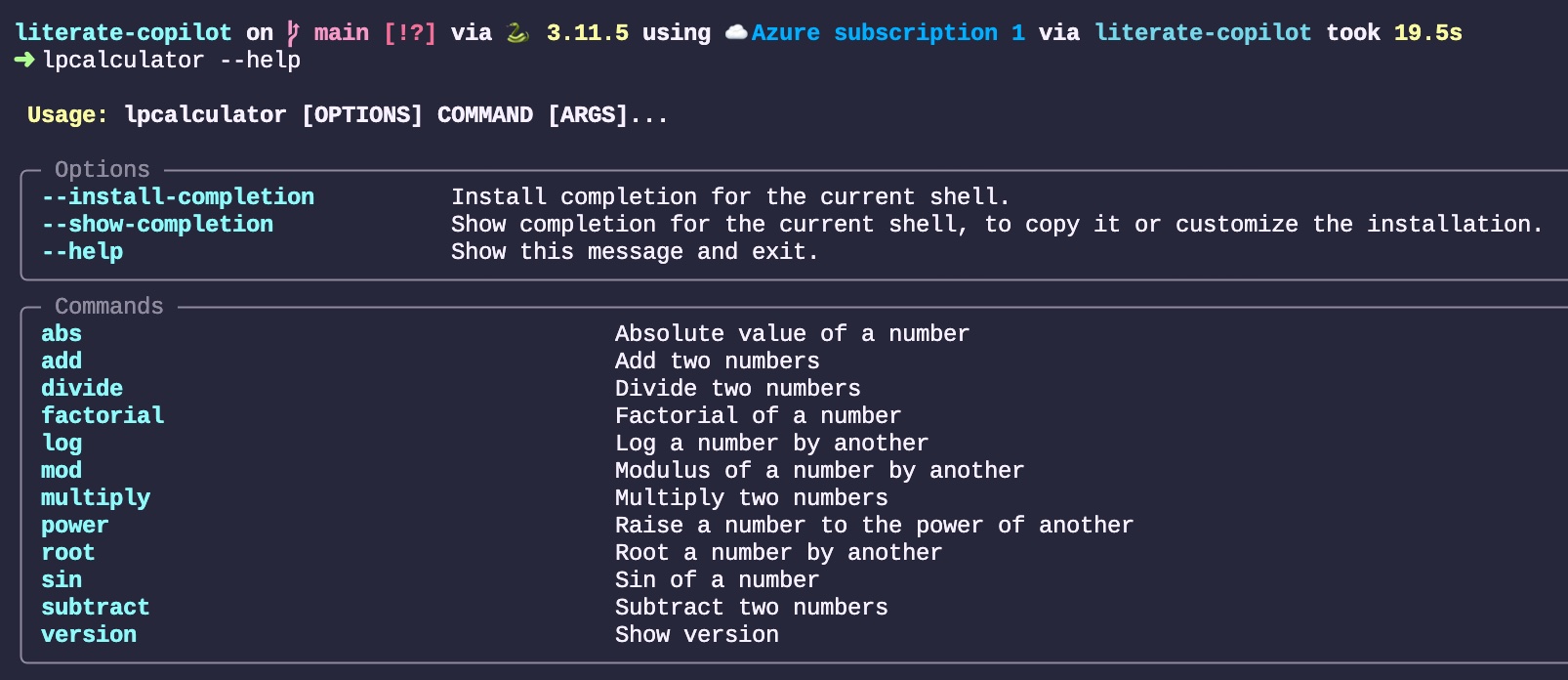
Adding Tests
Now that we have all these functions, I’d like to give Copilot a try at generating tests for each of them. To do this, I posed a very simple question to the newly generated release of Copilot Chat while having the 00_main.ipynb file open:
I would like to add tests for each of those commands.
By “those commands”, I was referring to what was currently displayed in the Workspace on my right, hoping that it would contextualize the request within the Workspace. The result Chat provided me with is:
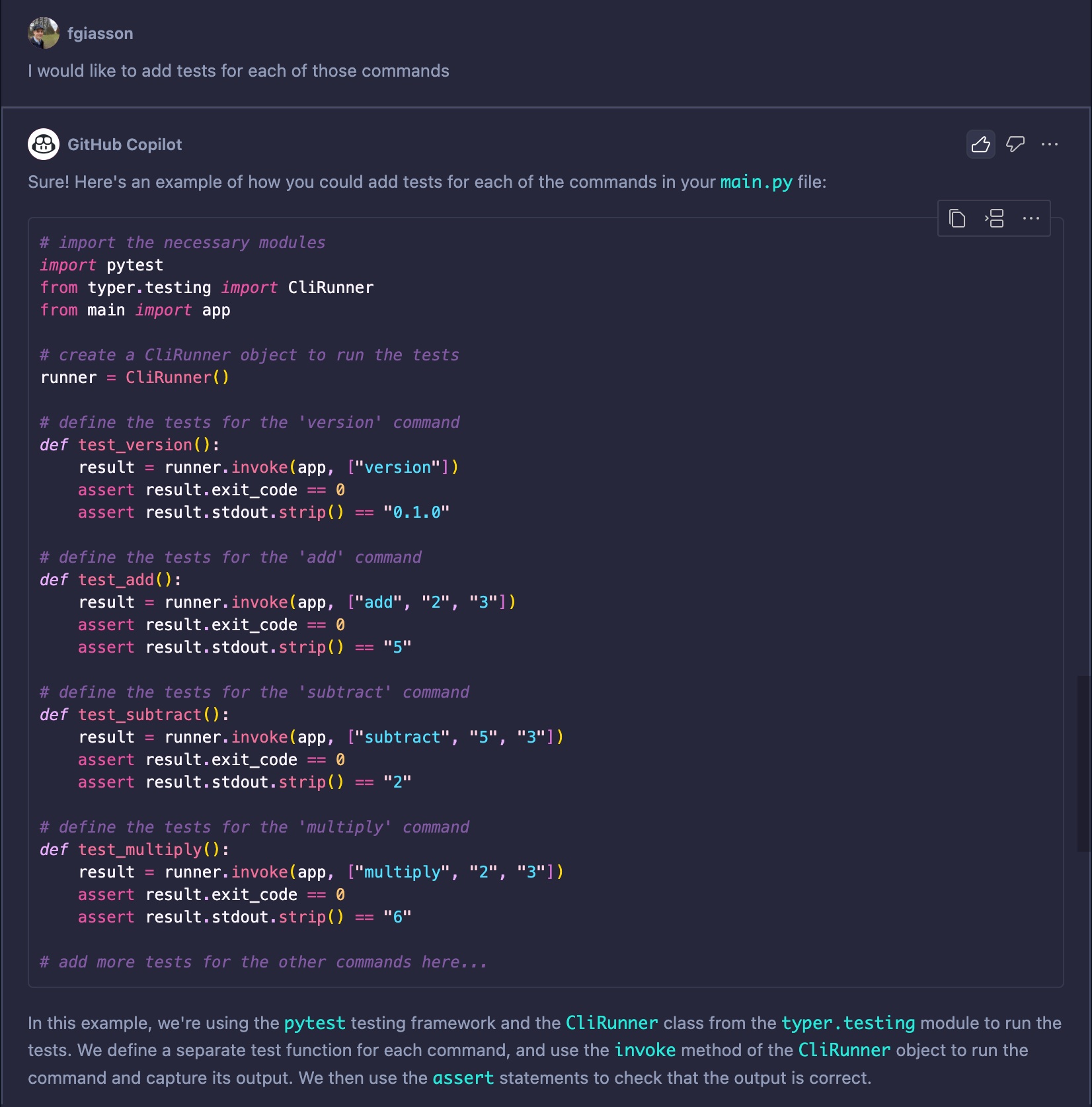
It is even aware that it is missing some from the list described in the introduction and continue to list them starting at the right place (divide):
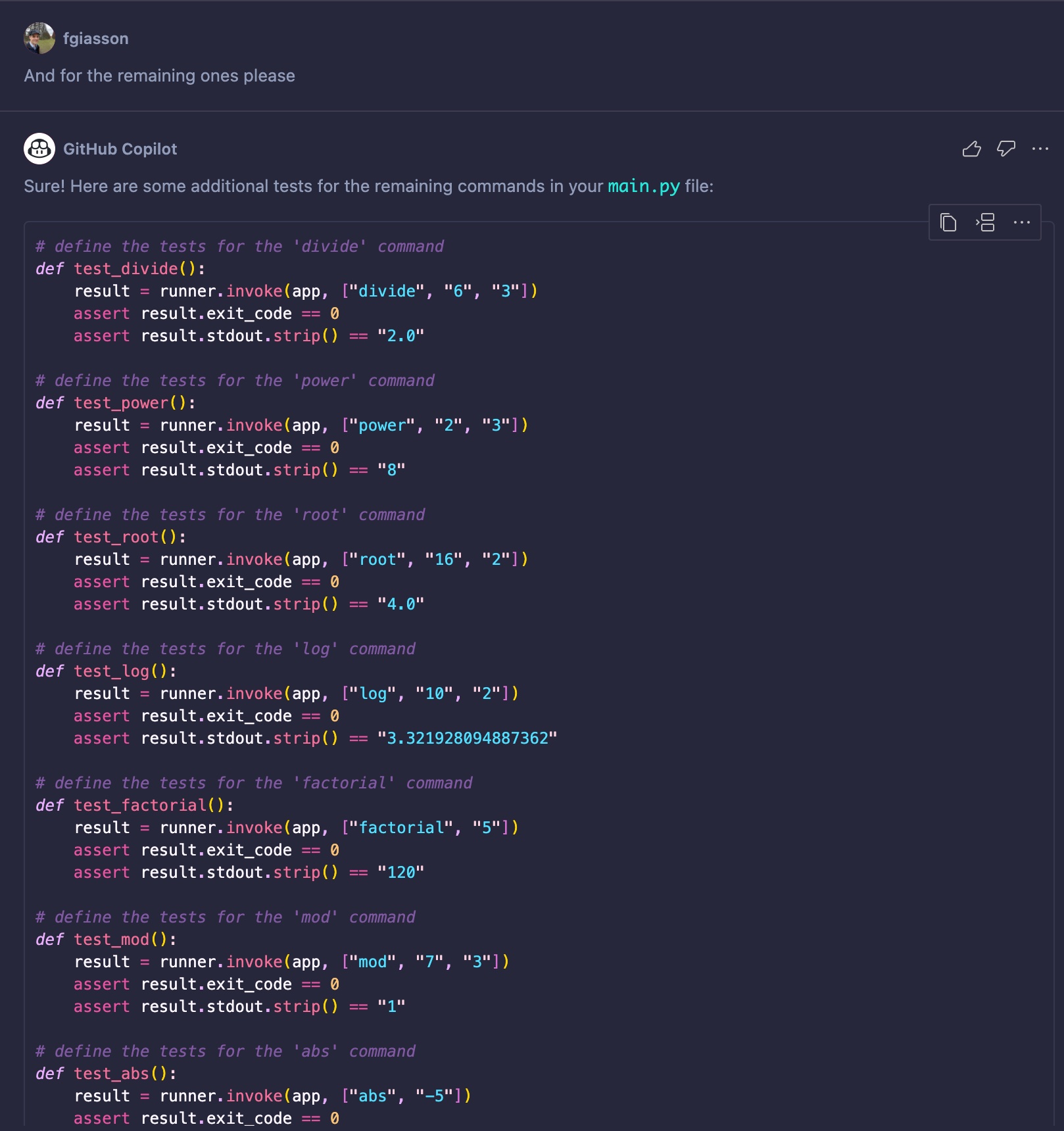
As you can see, it is fully aware of the context. It will produce one test per command, understanding that the commands print output to the terminal and that the functions do not return actual numbers. It will also attempt to use a CliRunner to execute the tests. While it doesn’t work out of the box, it’s certainly a step in the right direction.
Conclusion
This concludes the tests. It’s clear that Copilot is aware of a Workspace and contextualizes its suggestions accordingly. When working in a Jupyter notebook, it takes into account every code block.
This little experiment suggests to me that adopting a literate programming workflow and its principles can lead to better and more effective suggestions from LLMs like Copilot.
For thousands of years, humans have been expressing their thoughts in a sequential manner, from top to bottom. We’ve developed highly effective systems to organize these writings (you can explore the BIBO ontology for a glimpse into this). These systems have evolved and been refined up to the present day.
To me, this is the essence of Literate Programming. It’s about developing computer software in a more natural, thoughtful, and systematic human way.
Not many people in the industry share this perspective. However, what I’ve begun to explore in this blog post is how LLMs, along with integrated tools like GitHub’s Copilot, could potentially shift that perception. How Literate Programming could emerge as one of the top programming frameworks for effectively utilizing tools like Copilot.