| After more than 2 years, we are now finally releasing a new version of the UMBEL ontology and reference concept structure. One might think that we haven’t worked on the project all that time, but it is not strictly true. |
We did improve the mapping to external vocabularies/ontologies, we worked much on linking Wikipedia pages to the UMBEL structure, but we haven’t had time to release a new version… until now!
For people new to the ontology, UMBEL is a general reference structure of about 28,000 reference concepts, which provides a scaffolding to link and interoperate other datasets and domain vocabularies. Its main purpose is to have a coherent conceptual structure that we can use to link and interoperate unrelated data sources. But it can also be used as a conceptual structure to be used to describe information like any other ontologies.
What is new with the ontology?
The major change in UMBEL is not the structure itself, but the piece of software used to generate it. In fact, the previous system we developed for generating UMBEL was about 7 years old. It was a bit clunky and really not that easy to work with.
Based on our prior experience with UMBEL, we choose to dump it and to create a brand new UMBEL reference structure generator. This new generator has been developed in Clojure and uses the latest version of the OWL API. It makes the management of the structure much simpler, which means that it will help in releasing new UMBEL version more regularly. We also have a suite of tools to analyze the structure and to pinpoint possible issues.
Other than that, we updated the Schema.org, DBpedia Ontology and Geonames Ontology mappings to UMBEL. This is a major effort undertaken by Mike for this new version. The mappings are composed of:
- 754
rdfs:subClassOfrelationships betweenSchema.org classesand UMBEL reference concepts - 688
rdfs:subClassOfrelationships betweenDBpedia Ontology classesand UMBEL reference concepts - 682
rdfs:subClassOfrelationships betweenGeonames Ontology classesand UMBEL reference concepts
These new mappings will help manage data instances that use these external ontologies/schemas in a broader conceptual structure (which is UMBEL). This enables us to be able to reason over this external data using the UMBEL conceptual structure even if these external data sources didn’t originally use UMBEL to describe their data. That is one of the main features of UMBEL.
We also managed to add a few hundred UMBEL reference concepts. Most of them were added to create these new linkages with the external ontologies. Others have been added because they were improving the overall structure.
A few weeks back, we found an issue with the umbel:superClassOf assignations, which has also now been resolved in version 1.10.
In the previous versions of UMBEL, the preferred labels were not unique. There were a few hundred of the concepts that were having the same preferred labels. This was not an issue in itself, but this was not a best practice to create an ontology. We managed to remove all these non-distinct preferred labels and to make all of them unique.
We added a few skos:broader and skos:narrower relationships between some of the reference concepts. In the previous versions, all the relationships were skos:broaderTransitive and skos:narrowerTransitive properties only.
Finally we made sure that the entire UMBEL reference structure (Core + the Geo module) was absent of any inconsistencies and that it was satisfiable.
What is new with the portal and web services?
This new version of UMBEL also led us to create a few new features to the UMBEL website. The most apparent feature is the new External Linkage section that may appear at the top of a reference concept page (obviously, it will not appear if there are no external links for a given reference concept). This section shows you the linkage between the UMBEL reference concept and other external classes:

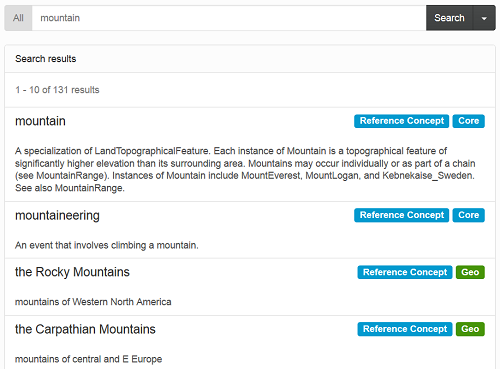
Another feature that you will notice on this screenshot is the Core blue tag at the right of the URI of the reference concept. This tag is used to tell you from where the reference concept is coming. Another tag that you may encounter is the green Geo tag, which tells you that the reference concept comes from the UMBEL Geo module. The same tags appear in the search resultsets:
What is next?
Because UMBEL is an ontology, by nature it will always evolve over time. Things change, and the way we see the World can always improve.
For the next version of UMBEL, we will analyze the entire UMBEL reference concept structure using different algorithms, heuristics and other techniques to analyze the conceptual structure and to find conceptual gaps in it. The goal of this analysis is to tighten the structure, to have a better conceptual hierarchy and a more fine-grained one.
Other things we want to do in other coming versions are to improve the Super Types structure of UMBEL. As you may know, many of the Super Types are non disjoint because some of the concepts belong to multiple Super Type classes. What we want to do here is to create new Super Types classes that are the intersection between two, or more, Super Types that will be used to categorize these concepts that belong to multiple Super Types. That way, we will end-up with a better classification of the UMBEL reference concepts from a Super Types standpoint.
Another thing we want to do related to the UMBEL web services is to update them such that you can query the linkage to the external ontologies. For now, you can see the linkage when querying the sub-classes and super-classes of a reference concept. But you cannot query the web services this way: give me all the sub-classes-of the http://schema.org/FireStation class, for example.
As you can see, the UMBEL ontology and web services will continue to evolve over time to enable new ways to leverage the conceptual structure and external data sources.