Extract Structured Content, Tag Concepts & Entities
Cognonto is brand new. At its core, it uses a structure of nearly 40 000 concepts. It has about 138,000 links to external classes and concepts that defines huge public datasets such as Wikipedia, DBpedia and USPTO. Cognonto is not a children’s toy. It is huge and complex… but it is very usable. Before digging into the structure itself, before starting to write about all the use cases that Cognonto can support, I will first cover all of the tools that currently exist to help you understand Cognonto and its conceptual structure and linkages (called KBpedia).
The embodiment of Cognonto that people can see are the tools we created and that we made available on the cognonto.com web site. Their goal is to show the structure at work, what ties where, how the conceptual structure and its links to external schemas and datasets help discover new facts, how it can drive other services, etc.
This initial blog post will discuss the demo section of the web site. What we call the Cognonto demo is a web page crawler that analyzes web pages to tag concepts, to tag named entities, to extract structured data, to detect language, to identity topics, and so forth. The demo uses the KBpedia structure and its linkages to Wikipedia, Wikidata, Freebase and USPTO to tag content that appears in the analyzed web pages. But there is one thing to keep in mind: the purpose of Cognonto is to link public or private datasets to the structure to expand its knowledge and make these tools (like the demo) even more powerful. This means that a private organization could use Cognonto, add their own datasets and link their own schemas, to improve their own version of Cognonto or to tailor it for their own purpose.
Let’s see what the demo looks like, what is the information it extracts and analyzes from any web page, and how it ties into the KBpedia structure.
Analyzing a web page
The essence of the Cognonto demo is to analyze a web page. The steps performed by the demo are:
- Crawling the web page’s content
- Extracting text content, defluffing and normalizing it
- Detecting the language used to write the content
- Extracting the copyright notice
- Extracting metadata from the web page (HTML, microformats, RDFa, etc.)
- Querying KBpedia to detect named entities
- Querying KBpedia to detect concepts
- Querying KBpedia to find information about the web page
- Analyzing extracted entities and concepts to determine the publisher
- Analyzing extracted concepts to determine the most likely topics
- Generating the analysis result set
To test the demo and see how it works, let’s analyze a piece of news recently published by CNN: Syria convoy attack: US blames Russia. You can start the analysis process by following this link. The first page will be:
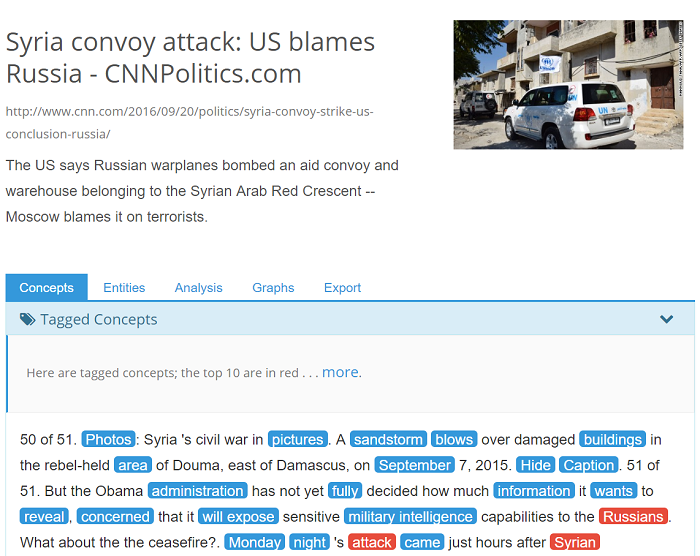
What the demo shows is the header of the analyzed web page. The header is composed of the title of the web page and possibly a short description and an image. All of this information comes from the extracted metadata content of the page. Then you are presented with 5 tabs:
Concepts: which shows the body content and extracted metadata of the web page tagged with all detected KBpedia conceptsEntities: which shows the body content and extracted metadata of the web page tagged with all detected KBpedia named entities that exists in the knowledge baseAnalysis: which shows all the different kinds of analysis performed by the demographs: which shows how the topics found during the topic analysis step ties into the KBpedia conceptual structureexport: which shows you what the final resultset looks like
Concepts tab
The concepts tab is the first one that is presented to you. All of the concepts that exist in KBpedia (among its ~40 000 concepts) will appear in the body content of the web page and its extracted metadata. There is one important thing to keep in mind here: the demo does detect what it considers to be the body content of the web page. It will defluff it, which means that it will remove the header, footer and sidebars and all other irrelevant content that can appear in the page surrounding the body content of that page. The model used by the demo works better on articles like web pages. So there are some web pages that may not end with much extracted body content for that very reason.
All of the concepts that appear in red are the ones that the demo considers to be the core concepts of the web page. The ones in blue are all of the other ones. If you mouse over any of these tagged terms, you will be presented a contextual menu that will show you one or multiple concepts that may refer to that surface form (the word in the text). For example, if you mouse over administration, you will be presented with two possible concepts for that word:

However, if you do the same for airstrikes then you will be presented a single unambiguous concept:

If you click on any of those links, then you will be redirected to a KBpedia reference concept view page. You will see exactly how that concepts ties into the broader KBpedia conceptual structure. You will see all of its related (direct and inferred) concepts, and how it links to external schemas, vocabularies and ontologies. It will show you lists of related entities, etc.
What all of this shows you is how these tagged concepts are in fact windows to a much broader universe that can be understood because all of its information is fully structured and can be reasoned upon. This is the crux of the demo. It shows that the content of a web page is not just about its content, but its entire context as well.
Entities tab
The entities tab presents information in exactly the same manner as the Concepts tab. However the content that is tagged is different. Instead of tagging concepts, we tag named entities. These entities (in the case of this demo) come from the entities datasets that we linked to KBpedia, namely: Wikipedia, Wikidata, Freebase and USPTO. These are a different kind of window than the concepts. These are the named things of this World that we detect in the content of the web page.
But there is one important thing to keep in mind: these are the named things that exist in the knowledge base at that moment. The demo is somewhat constrained to tens of millions of fully structured named entities that comes from these various public data sources. However the purpose of a knowledge base is to be nurtured and extended. Organizations could add private datasets into the mix to augment the knowledge of the system or to specialize it to specific domains of interest.
Another important thing to keep in mind is that we have constrained this demo to a specific domain of things, namely organizations. The demo is only considering a subset of entities from the KBpedia knowledge base, namely anything that is an organization. This shows how KBpedia can be sliced and diced to be domain specific. How millions of entities can be categorized in different kinds of domains id what leads to purposeful dedicated services.
The tag that appears in orange in the text is the organization entity that has been detected to be the organization that published that web page. All the other entities appear in blue. If you click on one of these entities, then you will be redirected to the entity view page. That page will show you all the structured information we have related to these entities in the knowledge base, and you will see how it ties to the KBpedia conceptual structure.
Analysis tab
The analysis tab is to core of the demo. It presents some analysis of the web page that uses the tagged concepts and entities to generate new information about the page. These are just some analysis we developed for the demo. All kinds of other analysis could be created in the future depending on the needs of our clients.
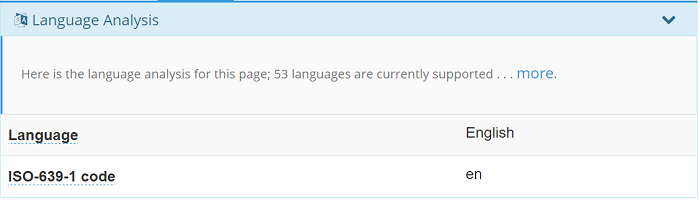
Language analysis
The first thing we detect is the language used to write the web page. The analysis is performed on the extracted body content of the page. We can detect about 125 languages at the moment. Cognonto is multilingual at its core, but at the moment we only configured the demo to analyze English web pages. Non-English web pages can be analyzed, but only English surface forms will be detected.
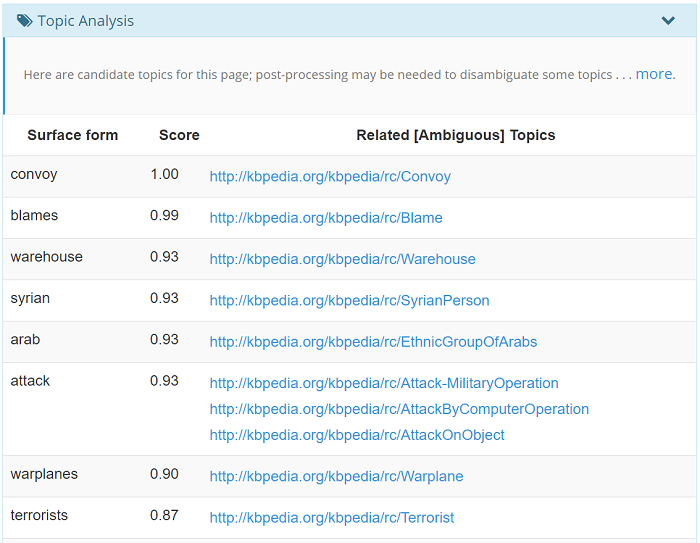
Topic analysis
The topic analysis section shows what the demo considers to be the most important concepts detected in the web page. Depending on a full suite of criteria, one concept will score higher than another. Note that all the concepts exist in the KBpedia conceptual structure. This means that we don’t simply “tag” a concept. We tag a concept that is part of an entire structure with hundreds and thousands of parents or children concepts, and linked to external schemas, vocabularies and ontologies. Again, these are not simple tags, these are windows into a much broader [conceptual] world.
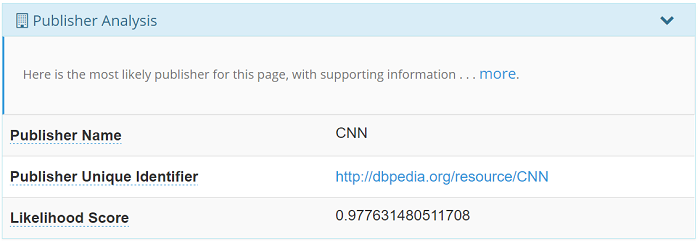
Publisher analysis
The publisher analysis section shows what we consider to be the organization that published the web page. This analysis is much more complex in its processing. It incurs an analysis pipeline that includes multiple machine learning algorithms. However there is one thing that distinguishes it at its core than other more conventional machine learning pipelines: the heavy leveraging of the KBpedia conceptual structure. We use the tagged named entities the demo discovered, we check their types and then we analyze their structure within KBpedia, by using their SuperTypes for further analysis. Then we check the occurrence of their placements in the page and we compute a final likelihood score and we determine if one of these tagged entities can be considered the publisher of the web page.
Organizational Analysis
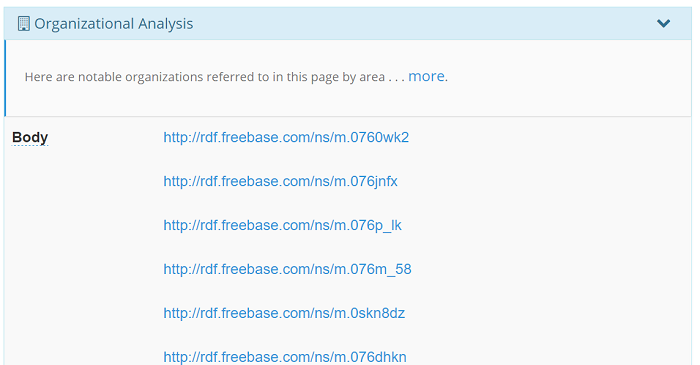
The organizational analysis is one of the steps that is performed by the Publisher analysis that we wanted to make explicit. What we do here is to show all the organization entities that we detected in the web page, and where in the web page (metadata, body content, etc.) they do appear.
The important thing to understand here is how we detect organization. We do not just check if the entities are of type Organization. What we do is to check if the entities are of type Organization by inference. What does that mean? It means that we use the KBpedia structure to keep all the tagged named entities that can be inferred to be an Organization. All of these organization entities are not defined to be of type kbpedia:Organization. However, what this analysis does is to check if the entities are of type kbpedia:Organization. But how is that possible? Cognonto does so by using the KBpedia structure, and its linkages to external vocabularies, schemas and ontologies, to determine which of the tagged named entities are of type kbpedia:Organization by inference.
Take a look at the kbpedia:Organization page. Take a look at all the Core structure and External structure linkage this single concept has with external conceptual structure. It is this structure that is used to determine if a named entity that exists in the KBpedia knowledge base is an Organization or not. There is no magic, but it is really powerful!
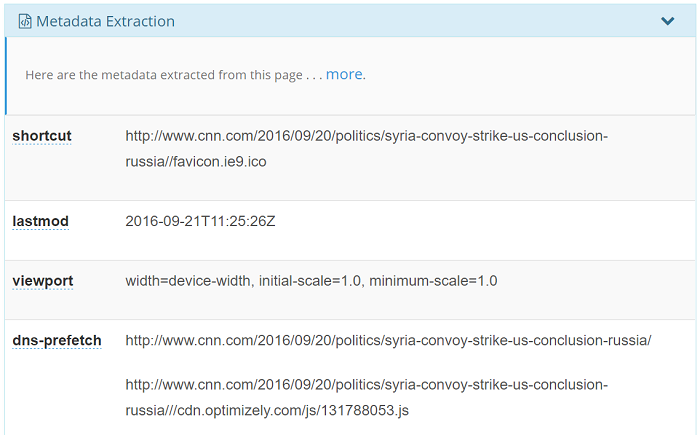
Metadata Extraction
All the extracted metadata by the demo is displayed at the end of the Analysis tab. This meta data comes from the HTML meta elements or some embedded microdata and RDFa structured content. Everything that got detected is displayed in this tab.
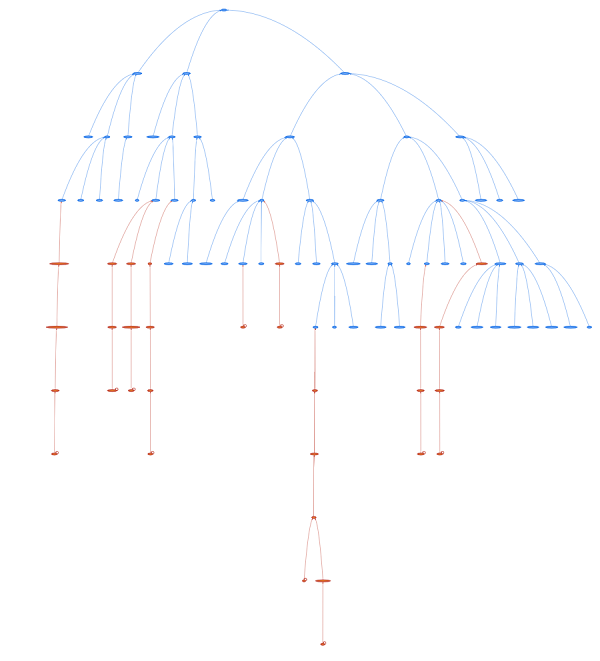
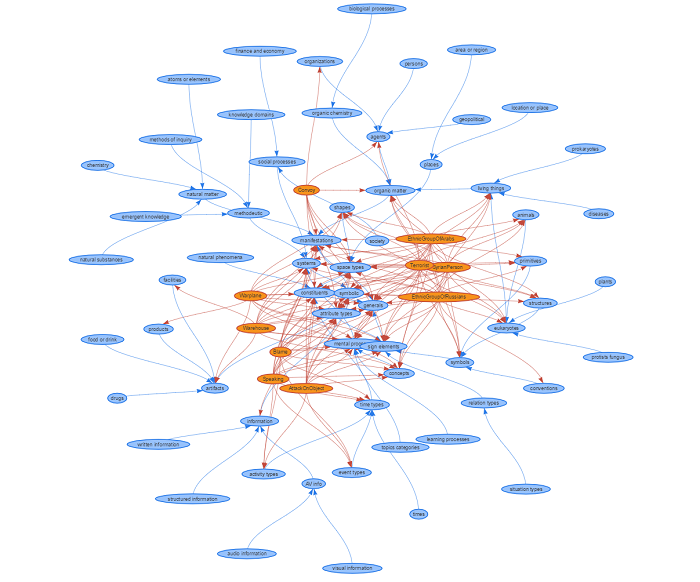
Graphs tab
The graph tab shows you a graphical visualization tool. The purpose is just to contextualize the identified concepts of the Topics analysis with the upper structure of KBpedia. It shows how everything is interconnected. But keep in mind that these are just tiny snapshots of the whole picture. There exists millions of links between these concepts and billions of inferred facts!
Here is a hierarchical view of the graph:
Here is a network view of that same graph:
Export tab
The export that is just a way for the user to visualize the resultset generated by Cognonto, enabling the web user interface to display the information you are seeing. It shows that all the information is structured and could be used by other computer systems for other means.
Conclusion
At the core of everything there is one thing: the KBpedia conceptual structure. It is what is being used across the board. It is what instructs machine learning algorithms, what helps us to analyze textual content such as web pages, this is what helps us to identify concepts and entities, it is what helps us to contextualize content, etc. This is the heart of Cognonto and everything else is just nuts and bolts. KBpedia can, and should, be extended with other private and public data sources. Cognonto/KBpedia is a living thing: it heals, it adapts and it evolves.