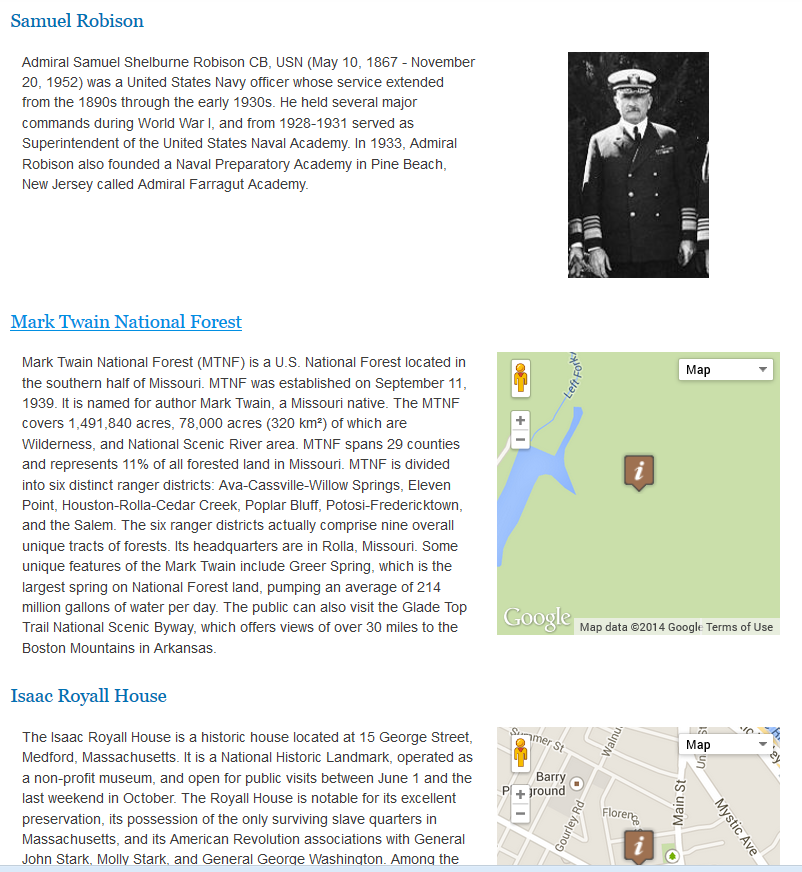
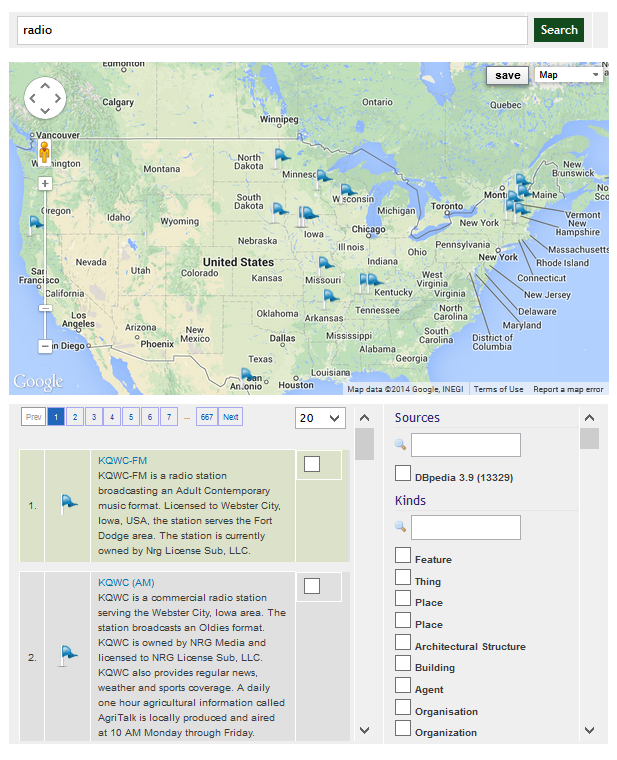
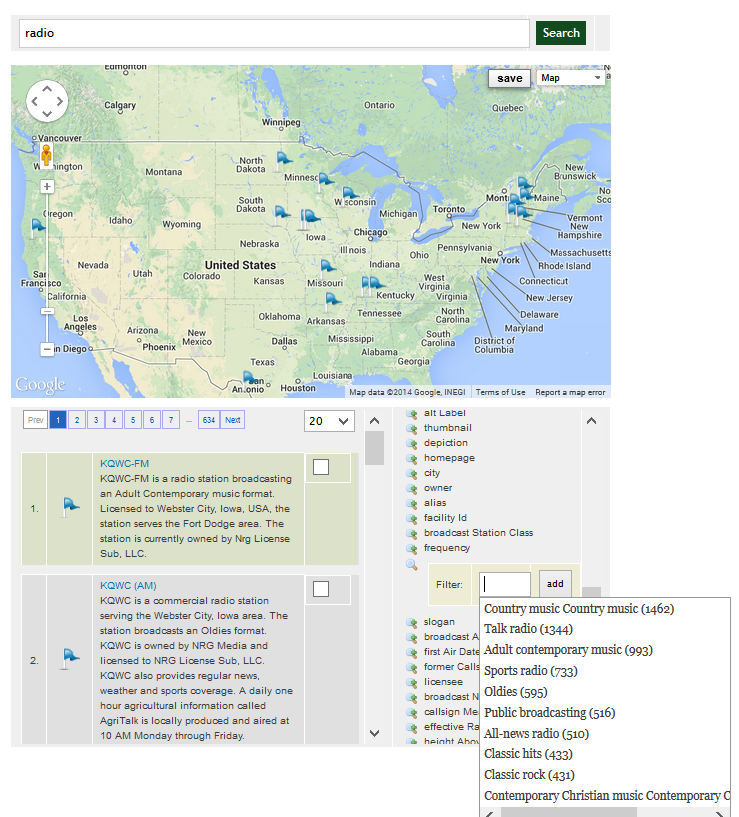
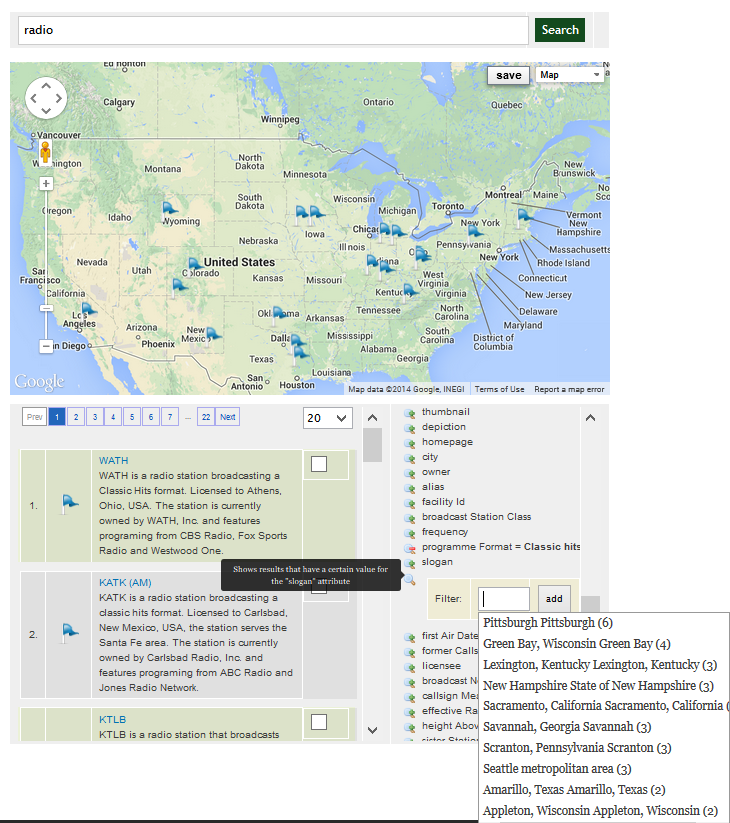
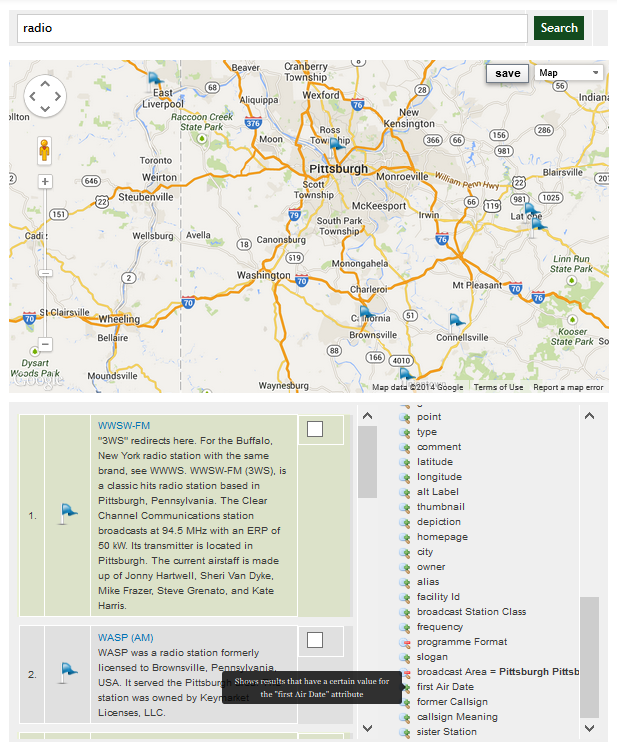
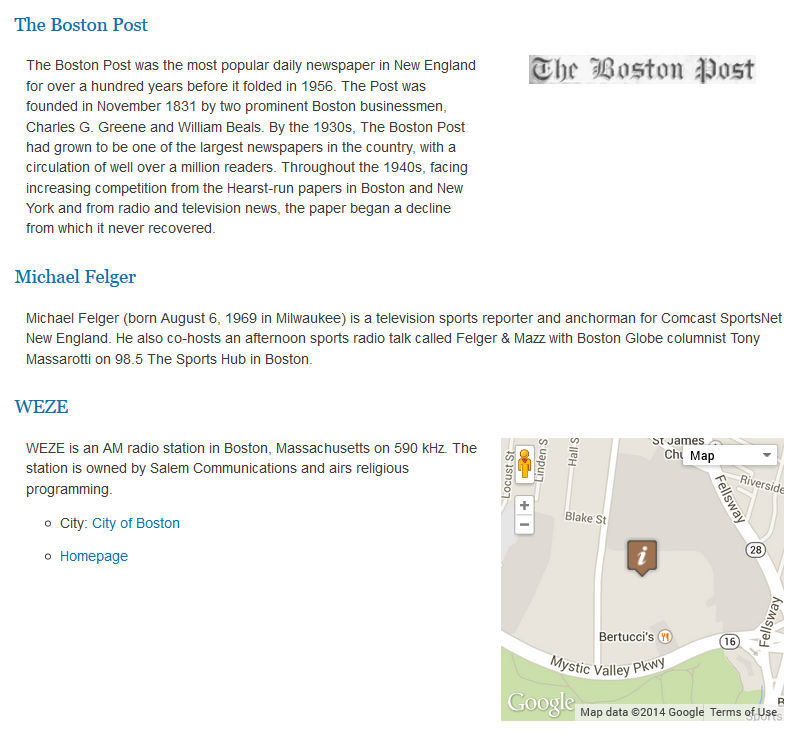
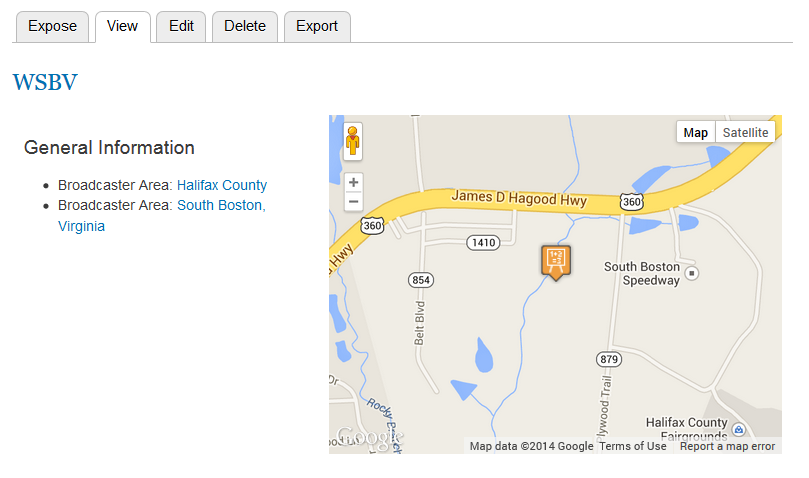
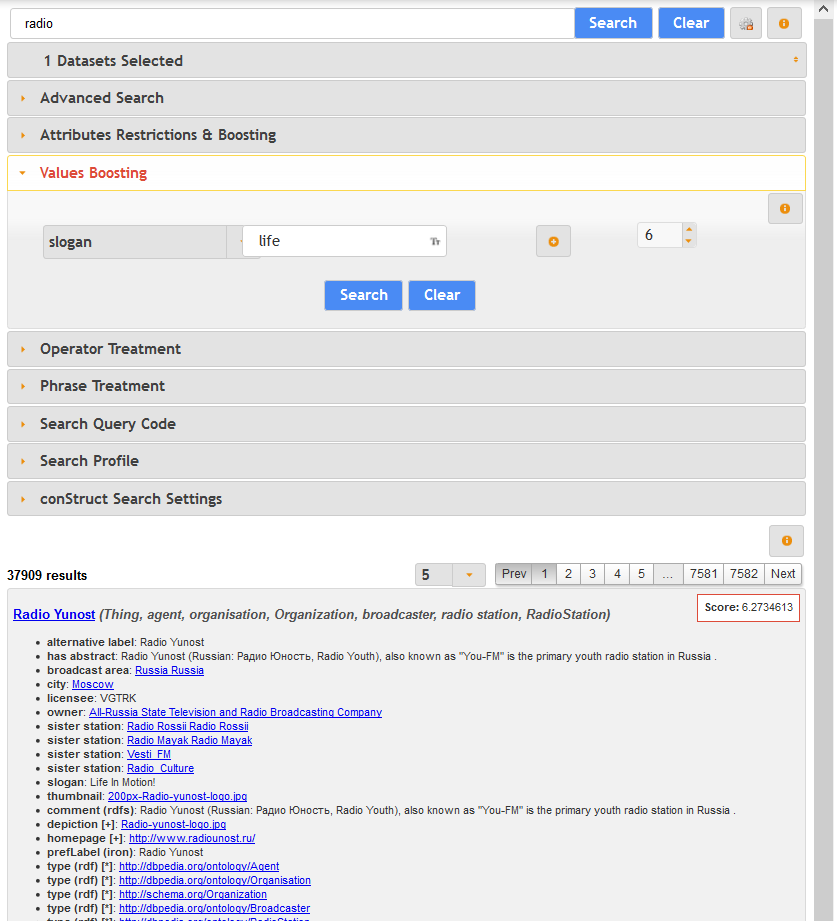
This first article or a series of two will show you how to load
DBpedia into a
Open Semantic Framework instance. A second article will be published that will show you how the 3.5 million entities present in DBpedia can be accessible from a
Drupal 7 installation. All the entities will be searchable, templatable, viewable, mappable, editabled and revisionable directly within Drupal.
Loading DBPedia into a OSF instance is not overly complex. Someone can easily manage to do it using this tutorial, and ending up with a OSF instance loaded with the full DBpedia dataset.
Creating a Open Semantic Framework Instance
The first step is to create a OSF instance. This tutorial uses the AWS EC2 OSF image. However, you can easily perform the same steps except that you should use the
OSF Installer to install OSF on your own Ubuntu 12.10 server.
To create the OSF instance we will use to load DBpedia, we use one of the following OSF 3.0 AMI:
| Region |
arch |
root store |
AMI |
| us-east-1 |
64-bit |
EBS |
ami-afe4d1c6 |
| us-west-1 |
64-bit |
EBS |
ami-d01b2895 |
| us-west-2 |
64-bit |
EBS |
ami-c6f691f6 |
| eu-west-1 |
64-bit |
EBS |
ami-883fd4ff |
| sa-east-1 |
64-bit |
EBS |
ami-6515b478 |
| ap-southeast-2 |
64-bit |
EBS |
ami-4734ab7d |
| ap-southeast-1 |
64-bit |
EBS |
ami-364d1a64 |
| ap-northeast-1 |
64-bit |
EBS |
ami-476a0646 |
Then to make things faster, we used a EC2 c3.4xlarge server with 75G of disk space.
In this tutorial, we are not re-configuring any passwords or settings for this vanilla instance. However, if you are to create an instance of your own, you should read the Creating and Configuring an Amazon EC2 AMI OSF Instance manual to configure it for you own purpose and to make it secure.
Note that most of the steps to load DBpedia into Virtuoso come from Jorn Hees’ article about this subject.
Also note that you should make sure to path the files in the following 3 commits. These issues have been found while writing this blog post, and haven’t (yet) made it into the AMI we use here: 88d6f1a782744a62bf83d52eceff695e0fee773b, 1389744b7dbf8f755a1bb9be468b3c51df75d6d8 and 719b4a776d43345e73847e6c785a4e9964b83a1c
Downloading DBpedia
The second step is to download all the DBpedia files that you want to use in your OSF instance. For this tutorial, we focus on the files where we can get the titles, abstracts, descriptions, all the mapped properties, the geolocalization of the entities, etc. You can download all these files by running the following commands:
[cc lang=’bash’ line_numbers=’false’]
[raw]
mkdir -p /usr/local/data/dbpedia/3.9/en
cd /usr/local/data/dbpedia/3.9/en
wget http://downloads.dbpedia.org/3.9/en/instance_types_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/mappingbased_properties_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/labels_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/short_abstracts_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/long_abstracts_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/images_en.nt.bz2
wget http://downloads.dbpedia.org/3.9/en/geo_coordinates_en.nt.bz2
bzip2 -d *
[/raw]
[/cc]
Loading DBpedia into Virtuoso
The next step is to use the Virtuoso’s RDF Bulk Loader to load all the DBpedia triples into Virtuoso. To do so, the first step we have to do is to create a new OSF dataset where the DBpedia entities will be indexed. To create the new dataset, we use the DMT (Datasets Management Tool) to create it. Note that the DMT is already installed on that OSF AMI 3.0.
[cc lang=’bash’ line_numbers=’false’]
[raw]
dmt -n –osf-web-services=”http://localhost/ws/” –uri=”http://dbpedia.org” –creator=”http://localhost/wsf/users/admin” –title=”DBpedia 3.9″ –group=”http://localhost/wsf/groups/administrators”
[/raw]
[/cc]
Then we have to create and configure the RDF Bulk Loader. The first step is to create the procedure file that will be used to import the tables and procedures into Virtuoso:
[cc lang=’bash’ line_numbers=’false’]
[raw]
cd /tmp/
[/raw]
[/cc]
Then create a file called VirtBulkRDFLoaderScript.vsql and add the following code in that new file:
[cc lang=’sql’ line_numbers=’false’]
[raw]
CREATE TABLE load_list (
ll_file VARCHAR,
ll_graph VARCHAR,
ll_state INT DEFAULT 0, — 0 not started, 1 going, 2 done
ll_started DATETIME,
ll_done DATETIME,
ll_host INT,
ll_work_time INTEGER,
ll_error VARCHAR,
PRIMARY KEY (ll_file))
ALTER INDEX load_list ON load_list PARTITION (ll_file VARCHAR)
;
CREATE INDEX ll_state ON load_list (ll_state, ll_file, ll_graph) PARTITION (ll_state INT)
;
CREATE TABLE ldlock (id INT PRIMARY KEY)
ALTER INDEX ldlock ON ldlock PARTITION (id INT)
;
INSERT INTO ldlock VALUES (0);
CREATE PROCEDURE
ld_dir (IN path VARCHAR, IN mask VARCHAR, IN graph VARCHAR)
{
DECLARE ls ANY;
DECLARE inx INT;
ls := sys_dirlist (path, 1);
FOR (inx := 0; inx < LENGTH (ls); inx := inx + 1)
{
IF (ls[inx] LIKE mask)
{
SET ISOLATION = 'serializable';
IF (NOT (EXISTS (SELECT 1 FROM DB.DBA.LOAD_LIST WHERE LL_FILE = path || '/' || ls[inx] FOR UPDATE)))
{
DECLARE gfile, cgfile, ngraph VARCHAR;
gfile := path || '/' || REPLACE (ls[inx], '.gz', '') || '.graph';
cgfile := path || '/' || regexp_replace (REPLACE (ls[inx], '.gz', ''), '\\-[0-9]+\\.n', '.n') || '.graph';
IF (file_stat (gfile) <> 0)
ngraph := TRIM (file_to_string (gfile), ‘ \r\n’);
ELSE IF (file_stat (cgfile) <> 0)
ngraph := TRIM (file_to_string (cgfile), ‘ \r\n’);
ELSE IF (file_stat (path || ‘/’ || ‘global.graph’) <> 0)
ngraph := TRIM (file_to_string (path || ‘/’ || ‘global.graph’), ‘ \r\n’);
ELSE
ngraph := graph;
IF (ngraph IS NOT NULL)
{
INSERT INTO DB.DBA.LOAD_LIST (ll_file, ll_graph) VALUES (path || ‘/’ || ls[inx], ngraph);
}
}
COMMIT WORK;
}
}
}
;
CREATE PROCEDURE
rdf_read_dir (IN path VARCHAR, IN mask VARCHAR, IN graph VARCHAR)
{
ld_dirr (path, mask, graph);
}
;
CREATE PROCEDURE
ld_dir_all (IN path VARCHAR, IN mask VARCHAR, IN graph VARCHAR)
{
DECLARE ls ANY;
DECLARE inx INT;
ls := sys_dirlist (path, 0);
ld_dir (path, mask, graph);
FOR (inx := 0; inx < LENGTH (ls); inx := inx + 1)
{
IF (ls[inx] <> ‘.’ AND ls[inx] <> ‘..’)
{
ld_dir_all (path||’/’||ls[inx], mask, graph);
}
}
}
;
CREATE PROCEDURE
ld_add (IN _fname VARCHAR, IN _graph VARCHAR)
{
–log_message (sprintf (‘ld_add: %s, %s’, _fname, _graph));
SET ISOLATION = ‘serializable’;
IF (NOT (EXISTS (SELECT 1 FROM DB.DBA.LOAD_LIST WHERE LL_FILE = _fname FOR UPDATE)))
{
INSERT INTO DB.DBA.LOAD_LIST (LL_FILE, LL_GRAPH) VALUES (_fname, _graph);
}
COMMIT WORK;
}
;
CREATE PROCEDURE
ld_ttlp_flags (IN fname VARCHAR)
{
IF (fname LIKE ‘%/btc-2009%’ OR fname LIKE ‘%.nq%’ OR fname LIKE ‘%.n4’)
RETURN 255 + 512;
RETURN 255;
}
;
CREATE PROCEDURE
ld_file (IN f VARCHAR, IN graph VARCHAR)
{
DECLARE gzip_name VARCHAR;
DECLARE exit handler FOR sqlstate ‘*’ {
ROLLBACK WORK;
UPDATE DB.DBA.LOAD_LIST
SET LL_STATE = 2,
LL_DONE = CURDATETIME (),
LL_ERROR = __sql_state || ‘ ‘ || __sql_message
WHERE LL_FILE = f;
COMMIT WORK;
log_message (sprintf (‘ File %s error %s %s’, f, __sql_state, __sql_message));
RETURN;
};
IF (f LIKE ‘%.grdf’ OR f LIKE ‘%.grdf.gz’)
{
load_grdf (f);
}
ELSE IF (f LIKE ‘%.gz’)
{
gzip_name := regexp_replace (f, ‘\.gz\x24’, ”);
IF (gzip_name LIKE ‘%.xml’ OR gzip_name LIKE ‘%.owl’ OR gzip_name LIKE ‘%.rdf’)
DB.DBA.RDF_LOAD_RDFXML (gz_file_open (f), graph, graph);
ELSE
TTLP (gz_file_open (f), graph, graph, ld_ttlp_flags (gzip_name));
}
ELSE
{
IF (f LIKE ‘%.xml’ OR f LIKE ‘%.owl’ OR f LIKE ‘%.rdf’)
DB.DBA.RDF_LOAD_RDFXML (file_open (f), graph, graph);
ELSE
TTLP (file_open (f), graph, graph, ld_ttlp_flags (f));
}
–log_message (sprintf (‘loaded %s’, f));
}
;
CREATE PROCEDURE
rdf_load_dir (IN path VARCHAR,
IN mask VARCHAR := ‘%.nt’,
IN graph VARCHAR := ‘http://dbpedia.org’)
{
DELETE FROM DB.DBA.LOAD_LIST WHERE LL_FILE = ‘##stop’;
COMMIT WORK;
ld_dir (path, mask, graph);
rdf_loader_run ();
}
;
CREATE PROCEDURE
ld_array ()
{
DECLARE first, last, arr, len, local ANY;
DECLARE cr CURSOR FOR
SELECT TOP 100 LL_FILE, LL_GRAPH
FROM DB.DBA.LOAD_LIST TABLE OPTION (INDEX ll_state)
WHERE LL_STATE = 0
FOR UPDATE;
DECLARE fill INT;
DECLARE f, g VARCHAR;
DECLARE r ANY;
WHENEVER NOT FOUND GOTO done;
first := 0;
last := 0;
arr := make_array (100, ‘any’);
fill := 0;
OPEN cr;
len := 0;
FOR (;;)
{
FETCH cr INTO f, g;
IF (0 = first) first := f;
last := f;
arr[fill] := VECTOR (f, g);
len := len + CAST (file_stat (f, 1) AS INT);
fill := fill + 1;
IF (len > 2000000)
GOTO done;
}
done:
IF (0 = first)
RETURN 0;
IF (1 <> sys_stat (‘cl_run_local_only’))
local := sys_stat (‘cl_this_host’);
UPDATE load_list SET ll_state = 1, ll_started = CURDATETIME (), LL_HOST = local
WHERE ll_file >= first AND ll_file <= last;
RETURN arr;
}
;
CREATE PROCEDURE
rdf_loader_run (IN max_files INTEGER := NULL, IN log_enable INT := 2)
{
DECLARE sec_delay float;
DECLARE _f, _graph VARCHAR;
DECLARE arr ANY;
DECLARE xx, inx, tx_mode, ld_mode INT;
ld_mode := log_enable;
IF (0 = sys_stat ('cl_run_local_only'))
{
IF (log_enable = 2 AND cl_this_host () = 1)
{
cl_exec ('checkpoint_interval (0)');
cl_exec ('__dbf_set (''cl_non_logged_write_mode'', 1)');
}
IF (cl_this_host () = 1)
cl_exec('__dbf_set(''cl_max_keep_alives_missed'',3000)');
}
tx_mode := bit_and (1, log_enable);
log_message ('Loader started');
DELETE FROM DB.DBA.LOAD_LIST WHERE LL_FILE = '##stop';
COMMIT WORK;
WHILE (1)
{
SET ISOLATION = 'repeatable';
DECLARE exit handler FOR sqlstate '40001' {
ROLLBACK WORK;
sec_delay := RND(1000)*0.001;
log_message(sprintf('deadlock in loader, waiting %d milliseconds', CAST (sec_delay * 1000 AS INTEGER)));
delay(sec_delay);
GOTO again;
};
again:;
IF (EXISTS (SELECT 1 FROM DB.DBA.LOAD_LIST WHERE LL_FILE = '##stop'))
{
log_message ('File load stopped by rdf_load_stop.');
RETURN;
}
log_enable (tx_mode, 1);
IF (max_files IS NOT NULL AND max_files <= 0)
{
COMMIT WORK;
log_message ('Max_files reached. Finishing.');
RETURN;
}
WHENEVER NOT FOUND GOTO looks_empty;
-- log_message ('Getting next file.');
SET ISOLATION = 'serializable';
SELECT id INTO xx FROM ldlock WHERE id = 0 FOR UPDATE;
arr := ld_array ();
COMMIT WORK;
IF (0 = arr)
GOTO looks_empty;
log_enable (ld_mode, 1);
FOR (inx := 0; inx < 100; inx := inx + 1)
{
IF (0 = arr[inx])
GOTO arr_done;
ld_file (arr[inx][0], arr[inx][1]);
UPDATE DB.DBA.LOAD_LIST SET LL_STATE = 2, LL_DONE = CURDATETIME () WHERE LL_FILE = arr[inx][0];
}
arr_done:
log_enable (tx_mode, 1);
IF (max_files IS NOT NULL) max_files := max_files - 100;
COMMIT WORK;
}
looks_empty:
COMMIT WORK;
log_message ('No more files to load. Loader has finished,');
RETURN;
}
;
CREATE PROCEDURE
rdf_load_stop (IN force INT := 0)
{
INSERT INTO DB.DBA.LOAD_LIST (LL_FILE) VALUES ('##stop');
COMMIT WORK;
IF (force)
cl_exec ('txn_killall (1)');
}
;
CREATE PROCEDURE
RDF_LOADER_RUN_1 (IN x INT, IN y INT)
{
rdf_loader_run (x, y);
}
;
CREATE PROCEDURE
rdf_ld_srv (IN log_enable INT)
{
DECLARE aq ANY;
aq := async_queue (1);
aq_request (aq, 'DB.DBA.RDF_LOADER_RUN_1', VECTOR (NULL, log_enable));
aq_wait_all (aq);
}
;
CREATE PROCEDURE
load_grdf (IN f VARCHAR)
{
DECLARE line ANY;
DECLARE inx INT;
DECLARE ses ANY;
DECLARE gr VARCHAR;
IF (f LIKE '%.gz')
ses := gz_file_open (f);
ELSE
ses := file_open (f);
inx := 0;
line := '';
WHILE (line <> 0)
{
gr := ses_read_line (ses, 0, 0, 1);
IF (gr = 0) RETURN;
line := ses_read_line (ses, 0, 0, 1);
IF (line = 0) RETURN;
DB.DBA.RDF_LOAD_RDFXML (line, gr, gr);
inx := inx + 1;
}
}
;
— cl_exec (‘set lock_escalation_pct = 110’);
— cl_exec (‘DB.DBA.RDF_LD_SRV (1)’) &
— cl_exec (‘DB.DBA.RDF_LD_SRV (2)’) &
[/raw]
[/cc]
Then we have to load it into Virtuoso using the following command:
[cc lang=’bash’ line_numbers=’false’]
[raw]
/usr/bin/isql-vt localhost dba dba VirtBulkRDFLoaderScript.vsql
[/raw]
[/cc]
Then we have to configure the RDF Bulk Loader. First enter in the isql interface:
[cc lang=’bash’ line_numbers=’false’]
[raw]
/usr/bin/isql-vt
[/raw]
[/cc]
Then copy/paste the following SQL code into the isql interface:
[cc lang=’sql’ line_numbers=’false’]
[raw]
— load the files to bulk-load
ld_dir_all(‘/usr/local/data/dbpedia/3.9’, ‘*.*’, ‘http://dbpedia.org’);
— list all the files that will be loaded
SELECT * FROM DB.DBA.LOAD_LIST;
— if unsatisfied use:
— delete from DB.DBA.LOAD_LIST and redo;
EXIT;
[/raw]
[/cc]
Then enter the isql interface again:
[cc lang=’bash’ line_numbers=’false’]
[raw]
/usr/bin/isql-vt
[/raw]
[/cc]
And copy/paste the following SQL lines:
[cc lang=’sql’ line_numbers=’false’]
[raw]
rdf_loader_run();
— will take approx. 2 hours with that EC2 server
checkpoint;
commit WORK;
checkpoint;
EXIT;
[/raw]
[/cc]
Configure the Datasets Management Tool
The next step is to properly configure the DMT to bulk load all the DBpedia entities into OSF.
Let’s step back, and explain what we are doing here. What we did with the steps above, is to use a fast method to import all the 3.5 million DBpedia records into Virtuoso. What we are doing now is to take these records, and to index them in the other underlying OSF systems (namely, the Solr full text search & faceting server). What the following steps will be doing is to load all these entities into the Solr index using the CRUD: Create web service endpoint. Once this step is finished, it means that all the DBpedia entities will be searchable and facetable using the OSF Search endpoint.
The first step is to edit the dmt.ini file to add information about the dataset to update:
[cc lang=’bash’ line_numbers=’false’]
[raw]
vim /usr/share/datasets-management-tool/dmt.ini
[/raw]
[/cc]
Then add the following section at the end of the file:
[cc lang=’ini’ line_numbers=’false’]
[raw]
[DBpedia]
datasetURI = “http://dbpedia.org”
baseURI = “http://dbpedia.org/”
datasetLocalPath = “/usr/local/data/dbpedia/3.9/en/”
converterPath = “/usr/share/datasets-management-tool/converters/default/”
converterScript = “defaultConverter.php”
converterFunctionName = “defaultConverter”
baseOntologyURI = “http://dbpedia.org/ontology/”
sliceSize = “500”
targetOSFWebServices = “http://localhost/ws/”
filteredFiles = “instance_types_en.nt”
forceReloadSolrIndex = “true”
[/raw]
[/cc]
Other Configurations to Speed-Up the Process
Now we will cover a few more configurations that can be performed in order to improve the speed of the indexation into OSF. You can skip these additional configuration steps, but if you do so, do not index more than 200 records per slice.
First search and edit the virtuoso.ini file. Then find the ResultSetMaxRows setting and configure it for 1000000 rows.
Then we have to increase the maximum memory allocated for the CRUD: Create web service endpoint. You have to edit the index.php file:
[cc lang=’bash’ line_numbers=’false’]
[raw]
vim /usr/share/osf/StructuredDynamics/osf/ws/crud/create/index.php
[/raw]
[/cc]
Then check around line #17 and increase the memory (memory_limit) to 1000M.
Then we have to change the maximum number of URIs that the CRUD: Read web service endpoint can get as input. By default it is 64, we will ramp it up to 500.
[cc lang=’bash’ line_numbers=’false’]
[raw]
vim /usr/share/osf/StructuredDynamics/osf/ws/crud/read/interfaces /DefaultSourceInterface.php
[/raw]
[/cc]
Then change 64 to 500 at line #25
Importing the DBpedia Ontology
before we start the process of importing the DBpedia dataset into OSF, we have to import the DBpedia Ontology into OSF such that it uses what is defined in the ontology to optimally index the content into the Solr index. To import the ontology, we use the OMT (Ontologies Management Tool).
[cc lang=’bash’ line_numbers=’false’]
[raw]
cd /data/ontologies/files/
wget http://downloads.dbpedia.org/3.9/dbpedia_3.9.owl.bz2
bzip2 -d dbpedia_3.9.owl.bz2
# Load the DBpedia Ontology
omt –load=”file://localhost/data/ontologies/files/dbpedia_3.9.owl” –osf-web-services=”http://localhost/ws/”
# Create the permissions access record for the administrator group to access this ontology
pmt –create-access –access-dataset=”file://localhost/data/ontologies/files/dbpedia_3.9.owl” –access-group=”http://localhost/wsf/groups/administrators” –access-perm-create=”true” –access-perm-read=”true” –access-perm-delete=”true” –access-perm-update=”true” –access-all-ws
# Regenerate the underlying ontological structures
omt –generate-structures=”/data/ontologies/structure/” –osf-web-services=”http://localhost/ws/”
[/raw]
[/cc]
Import DBpedia Into OSF
This is the final step: importing the DBpedia dataset into the OSF full text search index (Solr). To do so, we will use the DMT (Datasets Management Tool) that we previously configured to fully index the DBpedia entities into OSF:
[cc lang=’bash’ line_numbers=’false’]
[raw]
dmt -s -c dmt.ini –config-id=”DBpedia”
[/raw]
[/cc]
This process should take up to 24h with that kind of server.
Conclusion
At that point, the DBpedia dataset, composed of 3.5 million entities, is fully indexed into OSF. What that means is that all the 27 OSF web service endpoints can be used to query, manipulate and use these millions of entities.
However, there is even much more that come out-of-the-box by having DBpedia loaded into OSF. In fact, as we will see in the next article, this means that DBpedia becomes readily available to Drupal 7 if the OSF for Drupal module is installed on that Drupal 7 instance.
What that means is that the 3.5 million DBpedia entities can be searched via the Search API, can be manipulated via the Entity API, can be templated using the Drupal templating engine, etc. Then they can be searched and faceted directly on a map using the sWebMap OSF Widget. Then will be queriable via the OSF QueryBuilder that can be used to create all kind of complex search queries. Etc.
All this out-of-the-box.