The Cognonto demo is powered by an extensive knowledge graph called the KBpedia Knowledge Graph, as organized according to the KBpedia Knowledge Ontology (KKO). KBpedia is used for all kinds of tasks, some of which are demonstrated by the Cognonto use cases. KBpedia powers dataset linkage and mapping tools, machine learning training workflows, entity and concept extractions, category and topic tagging, etc.
The KBpedia Knowledge Graph is a structure of more than 39,000 reference concepts linked to 6 major knowledge bases and 20 popular ontologies in use across the Web. Unlike other knowledge graphs that analyze big corpuses of text to extract “concepts” (n-grams) and their co-occurrences, KBpedia has been created, is curated, is linked, and evolves using humans for the final vetting steps. KBpedia and its build process is thus a semi-automatic system.
The challenge with such a project is to be able to grow and refine (add or remove relations) within the structure without creating unknown conceptual issues. The sheer combinatorial scope of KBpedia means it is not possible for a human to fully understand the impact of adding or removing a relation on its entire structure. There is simply too much complexity in the interaction amongst the reference concepts (and their different kinds of relations) within the KBpedia Knowledge Graph.
What I discuss in this article is how Cognonto creates and then constantly evolves the KBpedia Knowledge Graph. In parallel with our creating KBpedia over the years, we also have needed to develop our own build processes and tools to make sure that every time something changes in KBpedia’s structure that it remains satisfiable and coherent.
The Importance of Testing Each Build
As you may experience for yourself with the Knowledge Graph browser, the KBpedia structure is linked to multiple external sources of information. Each of these sources (six major knowledge bases and another 20 ontologies) has its own world view. Each of these sources use its own concepts to organize its own structure.
What the KBpedia Knowledge Graph does is to merge all these different world views (and their associated instances and entities) into a coherent whole. One of the purposes of the KBpedia Knowledge Graph is to act as a scaffolding for integrating still further external sources, specifically in the knowledge domains relevant to specific clients.
One inherent characteristic of these knowledge sources is that they are constantly changing. Some may be updated only occasionally, others every year, others every few months, others every few weeks, or whatever. In the cases of Wikipedia and Wikidata, two of the most important contributors to KBpedia, thousands of changes occur daily. This dynamism of knowledge sources is an important fact since every time a source is changed, it may mean that its world view may have changed as well. Any of these changes can have an impact on KBpedia and the linkages we have to that external source.
Because of this dynamic environment, we do have to constantly regenerate the KBpedia Knowledge Graph and we constantly have to make sure that any changes in its structure or in the structure of the sources linked to it doesn’t make it insatisfiable nor incoherent.
It is for these reasons that we developed an extensive knowledge graph building process that includes a series of tests that are run every time that the knowledge graph get modified. Each new build is verified that it is still satisfiable and coherent.
The Build Process
The KBpedia Knowledge Graph build process has been developed over the years to create a robust workflow that enables us to regenerate KBpedia every time that something changed in it. The build process ensures that no issues are created every time we change something and regenerate KBpedia. Our build process also calculates a series of statistics and metrics that enable us to follow its evolution.
The process works as follow:
- Prepare log files
- Perform pre-checks. If any of these test fail, then the generation process won’t start. They check if:
- Any index file is corrupted
- All mentioned reference concept IDs exist
- All mentioned Super Type IDs exist
- No reference concept IDs are the same as Super Type IDs
- No new concepts IDs are the same as existing IDs
- Create the classes and individuals that define the knowledge graph
- Save the knowledge graph
- Generate the mapping between the reference concepts and the external ontologies/schemas/vocabularies
- Wikipedia
- Wikidata
- DBpedia
- Schema.org
- Geonames
- OpenCyc
- General Ontologies (Music Ontology, Bibliographic Ontology, FOAF, and 17 others…)
- Execute a series of post-creation tests
- Check for missing preferred labels
- Check for missing definitions
- Check for non-distinct preferred labels
- Check for reference concepts that do not have any reference to any Super Type (by inference) (also known as ‘orphans’)
- Check to make sure that the core KBpedia Knowledge Graph is satisfiable
- Check to make sure that the core KBpedia Knowledge Graph with its external linkages is satisfiable
- Check to make sure that the core KBpedia Knowledge Graph with its external linkages and extended inference relationships is satisfiable
- Finally, calculate a series of statistics and metrics.
It is important that we be able to do these builds and tests rapidly, so that we can move along new version releases rapidly. Remember, all changes to the KBpedia Knowledge Graph are manually vetted.
To accomplish this aim we actually build KBpedia from a set of fairly straightforward input files (for easy inspection and modification). We can completely rebuild all of KBpedia in less than two hours. About 45 minutes are required for building the overall structure and applying the satisfiability and coherency tests. The typology aspects of KBpedia and their tests adds another hour or so to complete the build. The rapidity of the build cycle means we can test and refine nearly in real time, useful when we are changing or refining big chunks of the structure.
An Escheresque Building Process
Building the KBpedia Knowledge Graph is like M.C. Escher’s hand’s drawing themselves. Because of the synergy between the Knowledge Graph reference concepts, its upper structure, its typologies and its numerous links to external linkages, any addition in one of these areas can lead to improvements in other areas of the knowledge graph. These improvements are informed by analyzing the metrics, statistics, and possible errors logged by the build process.
The Knowledge Graph is constantly evolving, self-healing and expanding. This is why that the build process and more importantly its tests are crucial to make sure that new issues are not introduced every time something changes within the structure.
To illustrate these points, let’s dig a little deeper into the KBpedia Knowledge Graph build process.
The Nature of the KBpedia Build Process
The KBpedia Knowledge Graph is built from a few relatively straightforward assignment files serialized in CSV. Each file has its purpose in the build process and is encoded using UTF-8 for internationalization purposes. KBpedia is just a set of simple indexes serialized as CSV files that can easily be exchanged, updated and re-processed.
The process is 100% repeatable and testable. If issues are found in the future that require a new step or a new test, it can easily be improved by plugging-in a new step or a new test into the processing pipeline. In fact, the current pipeline is the incremental result of years of working this process. I’m sure we will add more steps still as time goes on.
The process is also semi-automatic. Certain tests may cause the process to completely fail. If such a failure happens, then immediate actions are outputed in different log files. If the process does complete, then all kinds of log files and statistics about the KBpedia Knowledge Graph structure are written to the file system. Once completed, the human operator can easily check these logs and update the input files to improve something he may have found after analyzing the output files.
Building KBpedia is really an iterative process. It often is generated hundred of times before a new version is released.
Checking for Disjointedness and Inconsistencies
The core and more important test in the process is the satisfiability test that is run once the KBpedia Knowledge Graph is generated. An unsatisfiable class is a class that does not “satisfy” (is inconsistent with) the structure of the knowledge graph. In KBpedia, what needs to be satisfied are the disjoint assertions that exists at the upper level of the knowledge graph. If an assertion between two reference concepts (like a sub-class-of or an equivalent-to relationship) leads to an unsatisfiable disjoint assertion, then an error is raised and the issue will need to be fixed by the human operator.
Here is an example of an unsatisfiable class. In this example, someone wants to say that a musical group (kbpedia:MusicPerformanceOrganization) is a sub-class-of a musician (kbpedia:Musician). This new assertion is obviously an error (since musicians may also be individuals), but the human operator didn’t noticed it when he created the new relationship between the two reference concepts. So, how does the build process catch such errors? Here is how:
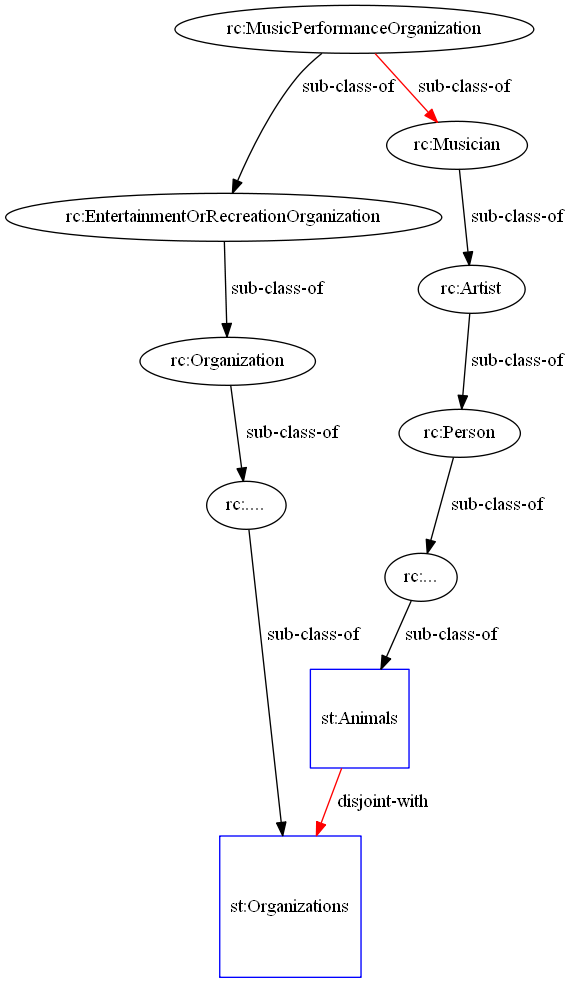
Because the two classes belong to two disjoint super classes, then the KBpedia generator finds this issue and returns an error along with logging report that explains why that new assertion makes the structure unsatisfiable. This testing and audit report is pretty powerful (and essential) to be able to maintain the integrity of the knowledge graph.
Unsatisfiability of Linked External Concepts
The satisfiability testing of external concepts linked to KBpedia is performed in two steps:
- The testing first checks the satisfiability of the core KBpedia Knowledge Graph and, then
- It checks the satisfiability of the KBpedia Knowledge Graph in relation to all of its other links to external data sources.
This second step is essential to make sure that any external concept we link to KBpedia is done properly and does not trigger any linking errors. In fact, we are trying to minimize the number of errors using the unsatisfiability testing. The process of checking if external concepts linked to the KBpedia Knowledge Graph satisfies the structure is the same. If their inclusion leads to such an issue, then it means that the links are the issue, since we know that the KBpedia core structure is satisfiable (since it was the previous step). Once detected, the linkage error(s) will be reviewed and fixed by the human operator and the structure will be regenerated. In the early phases of a new build, these fixes are accumulated and processed in batches. At the end of a new build, only one or a few errors remain to be corrected.
A Fully Connected Graph
Another important test is to make sure that the KBpedia Knowledge Graph is fully connected. We don’t want to have islands of concepts in the graph, we want to make sure that every concept is reachable using sub-class-of, super-class-of or equivalent-to relationships. If the build process detects that some concepts are disconnected from the graph, then new relationships will need to be created to reconnect the graph. These “orphan” tests ensure the integrity and completeness of the overall graph structure.
Typologies Have Their Own Tests
What is a typology? As stated by Merriam Webster, a typology is “a system used for putting things into groups according to how they are similar.” The KBpedia typologies, of which there are about 80, are the classification of types that are closely related, which we term Super Types. Three example Super Types are People, Activities and Products. The Super Types are found in the upper reaches of the KBpedia Knowledge Graph. (See further this article by Mike Bergman describing the upper structure of KBpedia and its relation to the typologies.) Thousands of disjointedness assertions have been defined between individual Super Types to other Super Types. These assertions enforce the fact that the reference concepts related to a Super Type A are not similar to the reference concepts related to, say, Super Type B.
These disjointedness assertions are a major factor in how we can rapidly slice-and-dice the KBpedia knowledge space to rapidly create training corpuses and positive and negative training sets for machine learning. These same disjointedness relationships are what we use to make sure that the KBpedia Knowledge Graph structure is satisfiable and coherent.
Another use of the typologies is to have a general overview of the knowledge graph. Each typology is a kind of lens that shows different parts of the knowledge graph. The build process creates a log of each of the typologies with all the reference conepts that belong to it. Similarly, the build process also creates a mini-ontology for each typology that can be inspected in an ontology editor. We use these outputs to more easily assess the various structures within KBpedia and to find possible conceptual issues as part of our manual vetting before final approvals.
Knowledge is Dynamic and So Must Be Builds and Testing
Creating, maintaining and evolving a knowledge graph the size of KBpedia is a non-trivial task. It is also a task that must be done frequently and rapidly whenever the underlying nature of KBpedia’s constituent knowledge bases dynamically changes. These demands require a robust build process with multiple logic and consistency tests. At every step we have to make sure that the entire structure is satisfiable and coherent. Fortunately, after development over a number of years, we now have processes in place that are battle tested and can continue to be expanded as the KBpedia Knowledge Graph constantly evolves.