Some of my recent work leaded me to heavily use Clojure to develop all kind of new capabilities for Structured Dynamics. The ones that knows us, knows that every we do is related to RDF and OWL ontologies. All this work with Clojure is no exception.
Recently, while developing a Domain Specific Language (DSL) for using the Open Semantic Framework (OSF) web service endpoints, I did some research to try to find some kind of simple Clojure DSL that I could use to generate RDF data (in any well-known serialization). After some time, I figured out that no such a thing was currently existing in the Clojure ecosystem, so I choose to create my simple DSL for creating RDF data.
The primary goal of this new project was to have a DSL that users could use to created RDF data that could be feed to the OSF web services endpoints such as the CRUD: Create or CRUD: Update endpoints.
What I choose to do is to create a new project called clj-turtle that generates RDF/Turtle code from Clojure code. The Turtle code that is produced by this DSL is currently quite verbose. This means that all the URIs are extended, that the triple quotes are used and that the triples are fully described.
This new DSL is mean to be a really simple and easy way to create RDF data. It could even be used by non-Clojure coder to create RDF/Turtle compatible data using the DSL. New services could easily be created that takes the DSL code as input and output the RDF/Turtle code. That way, no Clojure environment would be required to use the DSL for generating RDF data.
Installation
For people used to Clojure and Leinengen, you can easily install clj-turtle using Linengen. The only thing you have to do is to add Add [clj-turtle "0.1.3"] as a dependency to your project.clj.
Then make sure that you downloaded this dependency by running the lein deps command.
API
The whole DSL is composed of simply six operators:
rdf/turtle- Used to generate RDF/Turtle serialized data from a set of triples defined by
clj-turtle.
- Used to generate RDF/Turtle serialized data from a set of triples defined by
defns- Used to create/instantiate a new namespace that can be used to create the
clj-turtletriples
- Used to create/instantiate a new namespace that can be used to create the
rei- Used to reify a
clj-turtletriple
- Used to reify a
iri- Used to refer to a
URIwhere you provide the full URI as an input string
- Used to refer to a
literal- Used to refer to a
literalvalue
- Used to refer to a
a- Used to specify the
rdf:typeof an entity being described
- Used to specify the
Usage
Working with namespaces
The core of this DSL is the defns operator. What this operator does is to give you the possibility to create the namespaces you want to use to describe your data. Every time you use a namespace, it will generate a URI reference in the triple(s) that will be serialized in Turtle.
However, it is not necessary to create a new namespace every time you want to serialize Turtle data. In some cases, you may not even know what the namespace is since you have the full URI in hands already. It is why there is the iri function that let you serialize a full URI without having to use a namespace.
Namespaces are just shorthand versions of full URIs that mean to make your code cleaner an easier to read and maintain.
Syntactic rules
Here are the general syntactic rules that you have to follow when creating triples in a (rdf) or (turtle) statement:
- Wrap all the code using the
(rdf)or the(turtle)operator - Every triple need to be explicit. This means that every time you want to create a new triple, you have to mention the
subject,predicateand theobjectof the triple - A fourth “reification” element can be added using the
reioperator - The first parameter of any function can be any kind of value:
keywords,strings,integer,double, etc. They will be properly serialized as strings in Turtle.
Strings and keywords
As specified in the syntactic rules, at any time, you can use a string, a integer, a double a keyword or any other kind of value as input of the defined namespaces or the other API calls. You only have to use the way that is more convenient for you or that is the cleanest for your taste.
More about reification
Note: RDF reification is quite a different concept than Clojure’s reify macro. So carefully read this section to understand the meaning of the concept in this context.
In RDF, reifying a triple means that we want to add additional information about a specific triple. Let’s take this example:
[cc lang=”lisp”]
[raw]
(rdf
(foo :bar) (iron :prefLabel) (literal “Bar”))
[/raw]
[/cc]
In this example, we have a triple that specify the preferred label of the :bar entity. Now, let’s say that we want to add “meta” information about that specific triple, like the date when this triple got added to the system for example.
That additional information is considered the “fourth” element of a triple. It is defined like this:
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (iron :prefLabel) (literal “Bar”) (rei
(foo :date) (literal “2014-10-25” :type :xsd:dateTime)))
[/raw][/cc]
What we do here is to specify additional information regarding the triple itself. In this case, it is the date when the triple got added into our system.
So, reification statements are really “meta information” about triples. Also not that reification statements doesn’t change the semantic of the description of the entities.
Examples
Here is a list of examples of how this DSL can be used to generate RDF/Turtle data:
Create a new namespace
The first thing we have to do is define the namespaces we will want to use in our code.
[cc lang=”lisp”][raw]
(defns iron “http://purl.org/ontology/iron#”)
(defns foo “http://purl.org/ontology/foo#”)
(defns owl “http://www.w3.org/2002/07/owl#”)
(defns rdf “http://www.w3.org/1999/02/22-rdf-syntax-ns#”)
(defns xsd “http://www.w3.org/2001/XMLSchema#”)
[/raw][/cc]
Create a simple triple
The simplest example is to create a simple triple. What this triple does is to define the preferred label of a :bar entity:
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (iron :prefLabel) (literal “Bar”))
[/raw][/cc]
Output:
[cce]<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .[/cce]
Create a series of triples
This example shows how we can describe more than one attribute for our bar entity:
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (a) (owl :Thing)
(foo :bar) (iron :prefLabel) (literal “Bar”)
(foo :bar) (iron :altLabel) (literal “Foo”))
[/raw][/cc]
Output:
[cce]<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2002/07/owl#Thing> .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#altLabel> “””Foo””” .
[/cce]
Note: we prefer having one triple per line. However, it is possible to have all the triples in one line, but this will produce less readable code:
Just use keywords
It is possible to use keywords everywhere, even in (literals)
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (a) (owl :Thing)
(foo :bar) (iron :prefLabel) (literal :Bar)
(foo :bar) (iron :altLabel) (literal :Foo))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#> <http://www.w3.org/2002/07/owl#Thing> .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#altLabel> “””Foo””” .
[/cce]
Just use strings
It is possible to use strings everywhere, even in namespaces:
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (a) (owl “Thing”)
(foo “bar”) (iron :prefLabel) (literal “Bar”)
(foo “bar”) (iron :altLabel) (literal “Foo”))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#> <http://www.w3.org/2002/07/owl#Thing> .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#altLabel> “””Foo””” .
[/cce]
Specifying a datatype in a literal
It is possible to specify a datatype for every (literal) you are defining. You only have to use the :type option and to specify a XSD datatype as value:
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (foo :probability) (literal 0.03 :type :xsd:double))
[/raw][/cc]
Equivalent codes are:
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (foo :probability) (literal 0.03 :type (xsd :double)))
(rdf
(foo “bar”) (foo :probability) (literal 0.03 :type (iri “http://www.w3.org/2001/XMLSchema#double”)))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/foo#probability> “””0.03″””^^xsd:double .
[/cce]
Specifying a language for a literal
It is possible to specify a language string using the :lang option. The language tag should be a compatible ISO 639-1 language tag.
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (iron :prefLabel) (literal “Robert” :lang :fr))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Robert”””@fr .
[/cce]
Defining a type using the an operator
It is possible to use the (a) predicate as a shortcut to define the rdf:type of an entity:
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (a) (owl “Thing”))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#> <http://www.w3.org/2002/07/owl#Thing> .
[/cce]
This is a shortcut for:
[cc lang=”lisp”][raw]
(rdf
(foo “bar”) (rdf :type) (owl “Thing”))
[/raw][/cc]
Specifying a full URI using the iri operator
It is possible to define a subject, a predicate or an object using the (iri) operator if you want to defined them using the full URI of the entity:
[cc lang=”lisp”][raw]
(rdf
(iri “http://purl.org/ontology/foo#bar”) (iri “http://www.w3.org/1999/02/22-rdf-syntax-ns#type) (iri http://www.w3.org/2002/07/owl#Type))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2002/07/owl#Type> .
[/cce]
Simple reification
It is possible to reify any triple suing the (rei) operator as the fourth element of a triple:
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (iron :prefLabel) (literal “Bar”) (rei
(foo :date) (literal “2014-10-25” :type :xsd:dateTime)))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#subject> <http://purl.org/ontology/foo#bar> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate> <http://purl.org/ontology/iron#prefLabel> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#object> “””Bar””” .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://purl.org/ontology/foo#date> “””2014-10-25″””^^xsd:dateTime .
[/cce]
Reify multiple properties
It is possible to add multiple reification statements:
[cc lang=”lisp”][raw]
(rdf
(foo :bar) (iron :prefLabel) (literal “Bar”) (rei
(foo :date) (literal “2014-10-25” :type :xsd:dateTime)
(foo :bar) (literal 0.37)))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#subject> <http://purl.org/ontology/foo#bar> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate> <http://purl.org/ontology/iron#prefLabel> .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://www.w3.org/1999/02/22-rdf-syntax-ns#object> “””Bar””” .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://purl.org/ontology/foo#date> “””2014-10-25″””^^xsd:dateTime .
<rei:6930a1f93513367e174886cb7f7f74b7> <http://purl.org/ontology/foo#bar> “””0.37″”” .
[/cce]
Using clj-turtle with clj-osf
clj-turtle is meant to be used in Clojure code to simplify the creation of RDF data. Here is an example of how clj-turtle can be used to generate RDF data to feed to the OSF Crud: Create web service endpoint via the clj-osf DSL:
[cc lang=”lisp”][raw]
[require ‘[clj-osf.crud :as crud])
(crud/create
(crud/dataset “http://test.com/datasets/foo”)
(crud/document
(rdf
(iri link) (a) (bibo :Article)
(iri link) (iron :prefLabel) (literal “Some article”)))
(crud/is-rdf-n3)
(crud/full-indexation-mode))
[/raw][/cc]
Using the turtle alias operator
Depending on your taste, it is possible to use the (turtle) operator instead of the (rdf) one to generate the RDF/Turtle code:
[cc lang=”lisp”][raw]
(turtle
(foo “bar”) (iron :prefLabel) (literal “Robert” :lang :fr))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Robert”””@fr .
[/cce]
Merging clj-turtle
Depending the work you have to do in your Clojure application, you may have to generate the Turtle data using a more complex flow of operations. However, this is not an issue for clj-turtle since the only thing you have to do is to concatenate the triples you are creating. You can do so using a simple call to the str function, or you can create more complex processing using loopings, mappings, etc that end up with a (apply str) to generate the final Turtle string.
[cc lang=”lisp”][raw]
(str
(rdf
(foo “bar”) (a) (owl “Thing”))
(rdf
(foo “bar”) (iron :prefLabel) (literal “Bar”)
(foo “bar”) (iron :altLabel) (literal “Foo”)))
[/raw][/cc]
Output:
[cce]
<http://purl.org/ontology/foo#bar> <http://www.w3.org/1999/02/22-rdf-syntax-ns#> <http://www.w3.org/2002/07/owl#Thing> .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#prefLabel> “””Bar””” .
<http://purl.org/ontology/foo#bar> <http://purl.org/ontology/iron#altLabel> “””Foo””” .
[/cce]
Conclusion
As you can see now, this is a really simple DSL for generating RDF/Turtle code. Even if simple, I find it quite effective by its simplicity. However, even if it quite simple and has a minimum number of operators, this is flexible enough to be able to describe any kind of RDF data. Also, thanks to Clojure, it is also possible to write all kind of code that would generate DSL code that would be executed to generate the RDF data. For example, we can easily create some code that iterates a collection to produce one triple per item of the collection like this:
[cc lang=”lisp”][raw]
(->> {:label “a”
:label “b”
:label “c”}
(map
(fn [label]
(rdf
(foo :bar) (iron :prefLabel) (literal label))))
(apply str))
[/raw][/cc]
That code would generate 3 triples (or more if the input collection is bigger). Starting with this simple example, we can see how much more complex processes can leverage clj-turtle for generating RDF data.
A future enhancement to this DSL would be to add a syntactic rule that gives the opportunity to the user to only have to specify the suject of a triple the first time it is introduced to mimic the semi-colon of the Turtle syntax.


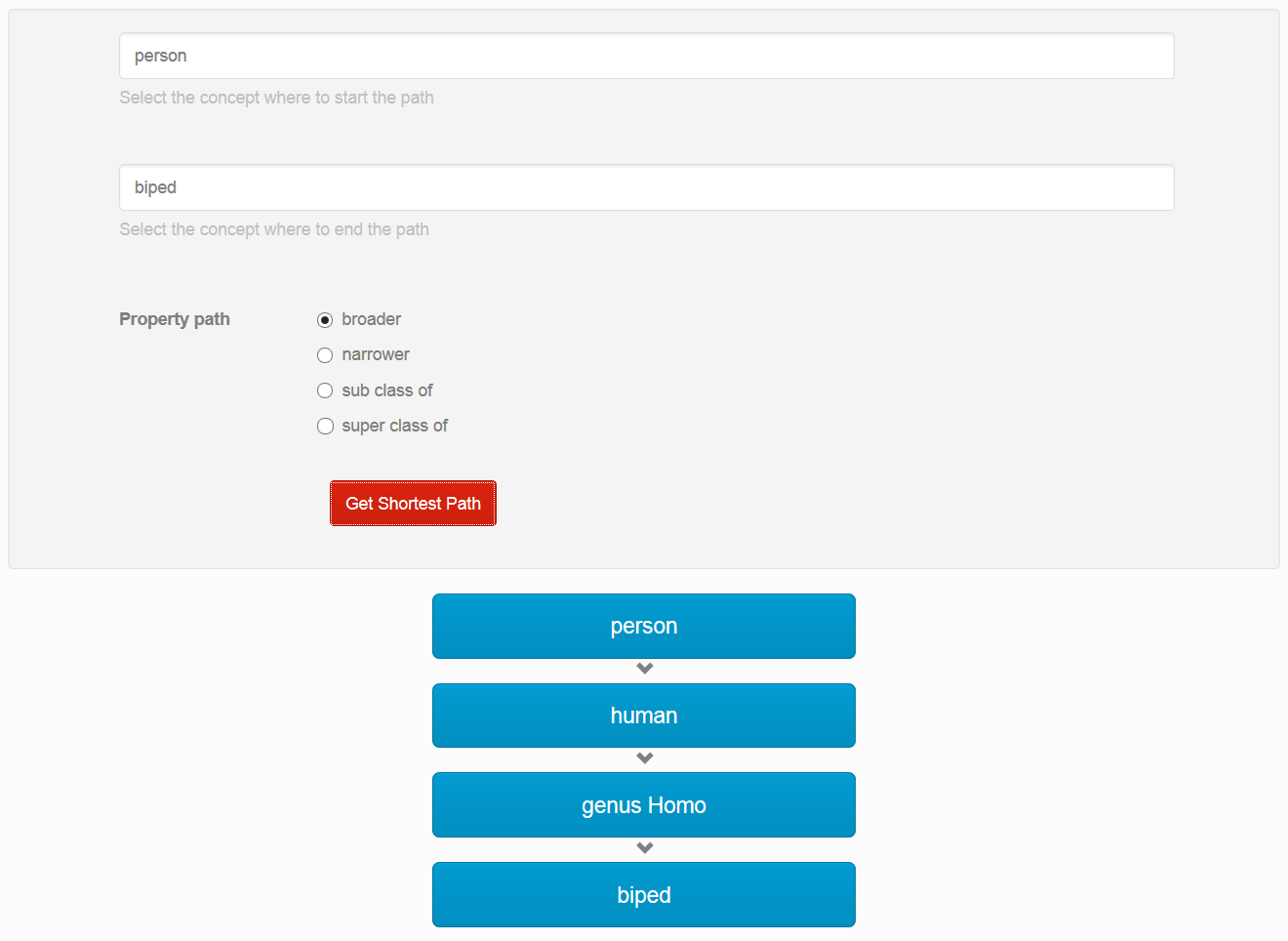
 where
where  is the graph,
is the graph,  is the set of all the vertices and
is the set of all the vertices and  is the set of all the edges of the same type that relates vertices.
is the set of all the edges of the same type that relates vertices.
 is the
is the  is the number of edges in the graph and
is the number of edges in the graph and  is the number of possible maximum number of edges.
is the number of possible maximum number of edges.
 is the
is the  be the length of the shortest path between
be the length of the shortest path between  and
and  . And
. And  . The diameter of the graph is defined as:
. The diameter of the graph is defined as:

 is the number of vertices in the graph
is the number of vertices in the graph  is the number of pairs of distinct vertices. Note that the number of pairs of distinct vertices is equal to the number of shortest paths between all pairs of vertices if we pick just one in case of a tie (two shortest paths with the same length).
is the number of pairs of distinct vertices. Note that the number of pairs of distinct vertices is equal to the number of shortest paths between all pairs of vertices if we pick just one in case of a tie (two shortest paths with the same length).
 is the number of neighborhood vertices,
is the number of neighborhood vertices,  is the maximum number of edges between the neighborhood vertices and
is the maximum number of edges between the neighborhood vertices and  is the set of all the neighborhood vertices for a given vertex
is the set of all the neighborhood vertices for a given vertex  .
. is represented by the sum of the clustering coefficient of all the vertices of a graph
is represented by the sum of the clustering coefficient of all the vertices of a graph 

 is the total number of shortest paths from node
is the total number of shortest paths from node  to node
to node  and
and  is the number of those paths that pass through
is the number of those paths that pass through  .
. which is about two thirds of a billion of edges. This is quite a lot of edges, but it is important to keep in mind since most of the following ratios are based on this maximum number of edges (connections) between the nodes of the UMBEL graph.
which is about two thirds of a billion of edges. This is quite a lot of edges, but it is important to keep in mind since most of the following ratios are based on this maximum number of edges (connections) between the nodes of the UMBEL graph.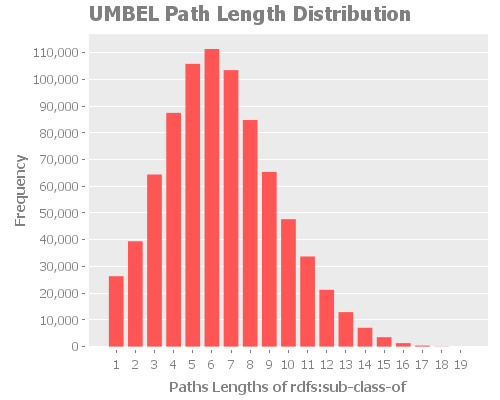
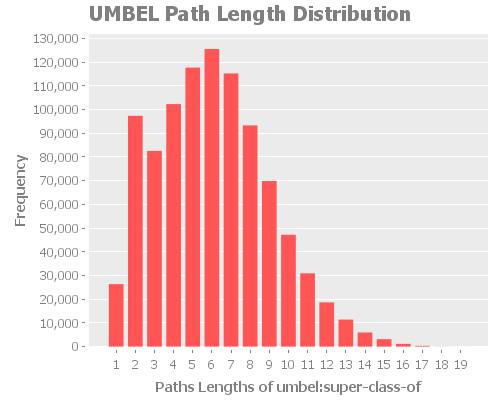


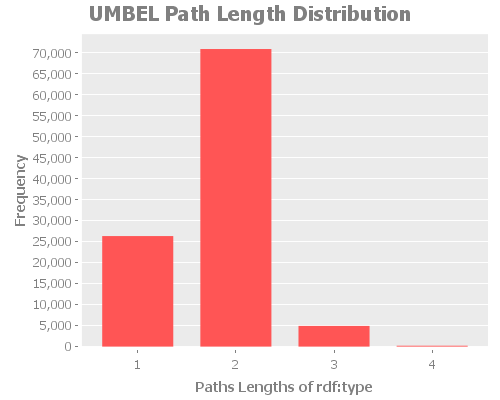
 where the property
where the property  is a transitive property. Since
is a transitive property. Since  .
. . The
. The