Introduction
I am proud to announce the new NOW (Neighbourhoods Of Winnipeg) semantic web portal! This new and innovative semantic web portal was publicly announced by the Mayor of Winnipeg City last week.
The NOW (Neighbourhoods of Winnipeg) portal is “a new Web portal (the “Portal”) produced by the City of Winnipeg to provide broad, dynamic and interactive access to local and neighbourhood information. Designed for easy access and use by all citizens, businesses, community organizations and Governments, the information on the site includes municipal data, census and demographic information, economic development information, historical data, much spatial and mapping information, and facilities for including and sharing data by external groups and constituencies.”
I would suggest you to read Mike Bergman’s blog post about this new semantic web portal to have the proper background about that initiative by the city of Winnipeg and how it uses the OSF (Open Semantic Framework) as its foundational technology stack.
This project has been the springboard that led to the Open Semantic Framework version 1.1. Multiple pieces of the framework have been developed in relation to this project, and more particularly pieces like the sWebMap semantic component and several improvements to the structWSF web services endpoints and conStruct modules for Drupal 6.
Development of the Portal
The development plan of this portal is composed of four major areas:
- Development of the data structure of the municipal domain by creating a series of ontologies
- Conversion of existing data asset using this new data structure
- Creation of the web portal by creating its design and by developing all the display templates
- Creation of new tools to let users interact with the data available on the portal
Structured Dynamics has been involved in #1, #2 and #4 by providing design and development resources, technology transfer sessions and material and supporting internal teams to create, maintain and deploy their 57 publicly available datasets.
The Data Structure
This technology stack does not have any meaning without the proper data and data structures (ontologies) in place. This gold mine of information is what drives the functionality of the portal.
The portal is driven by 12 ontologies: 2 internal and 10 external. The content of the 57 publicly available datasets is defined by the classes and properties defined in one of these ontologies.
The two internal ontologies have been created jointly by Structured Dynamics and the City of Winnipeg, but they are extended and maintained by the city only.
These ontologies are maintained using two different kind of tools:
- Protege
- structOntology
Protege is used for the big development tasks such as creating a big number of classes and properties, to do a big reorganization of the classes structure, etc.
structOntology is used for quick ontological changes to have an immediate impact on the behaviors of the portals such as label changes, SCO ontology property assignments to change the behavior of some of the tools that exist in the portal, etc.
structOntology can also be used by portal users to understand the underlying data structure used to define the data available on the portal. All users have access to the reading mode of the tool which let them browse, search and export the loaded ontologies on the portal.
The Data
Except for rare exceptions such as the historical photos, no new data has been created by the City of Winnipeg to populate this NOW portal. Most of its content comes from existing internal sources of data such as:
- Conventional relational databases
- GIS (Geographic Information System) on-top of relational databases
- Spreadsheets
All of the conventional relation databases and legacy data from the GIS systems has been converted into RDF using the FME Workbench ETL system. All of the FME workbench templates are mapping the relational data into RDF using the ontologies loaded into the portal. All of the geolocated records that exist in the portal come from this ETL process and have been converted using FME.
Some smaller datasets come from internal spreadsheets that got modified to comply with the commON spreadsheet format that is used to convert spreadsheet (CSV/TSV) data files into RDF.
All of the dataset creation and maintenance is managed internally by the City of Winnipeg using one of these two data conversion and importation processes.
Here are some internal statistics of the content that is currently accessible on the NOW portal.
General Portal
These are statistics related to different functionalities of the portal.
- Number of neighbourhoods: 236
- Number of community areas: 14
- Number of wards: 15
- Number of neighbourhood clusters: 23
- Number of major site sections: 7
- Total number of site pages: 428,019
- Static pages: 2,245
- Record-oriented pages: 425,874
- Dynamic (search-based) pages: infinite
- Number of documents: 1,017
- Number of images: 2,683
- Number of search facets: 1,392
- Number of display templates: 54
- Number of links: 1,067
- External links: 784
- Internal links: 283
Site Data
These statistics show the things that are available via the portal, what are their types, their properties, what is the quantity of data that is searchable, manipulable and exportable from the portal.
- Number of datasets: 57
- Number of records: 425,874
- Number of geolocational records: 418,869
- Point of interest (POI) records: 193,272
- Polygon records: 218,602
- Path (route) records: 6,995
- Number of geolocational records: 418,869
- Number of classes (types): 84
- Number of properties: 1,308
- Number of triple assertions: 8,683,103
Sharing Content
An important aspect of this portal is that all of the content is contextually available, in different formats, to all of the users of the portal. Whether you are browsing content within datasets, searching for specific pieces of content, or looking at a specific record page, you always have the possibility to get your hands on the content that is being displayed to you, the user, with a choice of five different data formats:
Export Page Content
All content pages can be exported in one of the formats outlined above. In the bottom right corner of these pages you will see a Export button that you can click to get the content of that page in one of these formats.
Export Search Content
Every time you do a search on the portal, you can export the results of that search in one of the formats outlined above. You can do that by selecting the Export tab, and by selecting one of the formats you want to use for exporting the data.
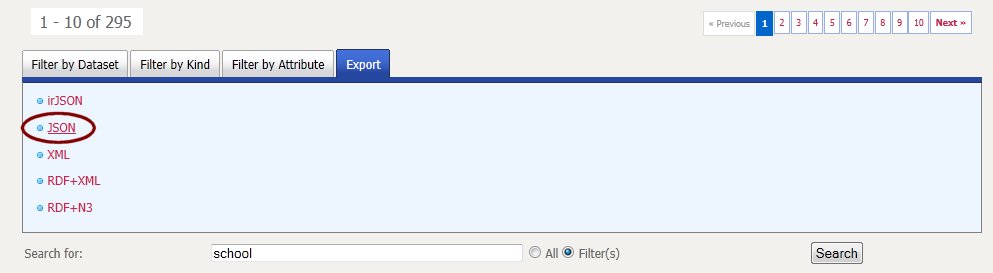
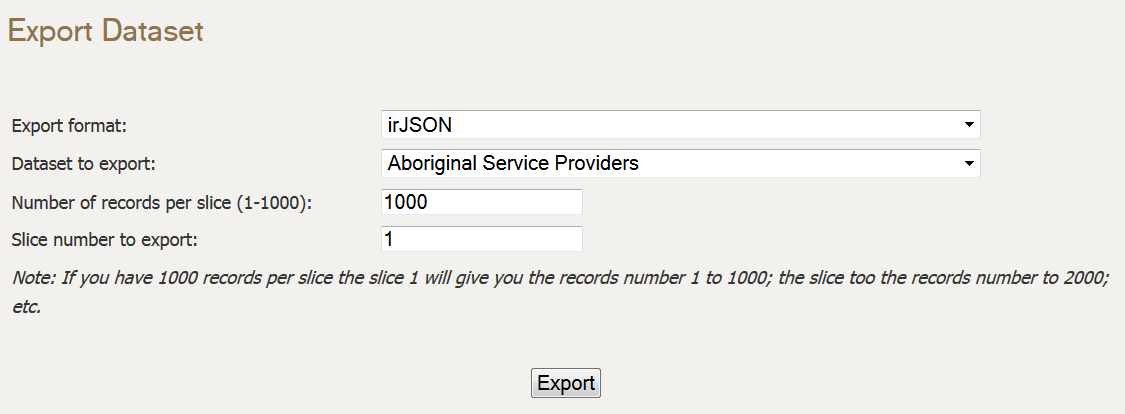
Export Datasets
You can export any publicly available dataset from the portal. These datasets have to be exported in slices if they are too big to fit in a single slice. The datasets can be exported in one of the formats mentioned above.
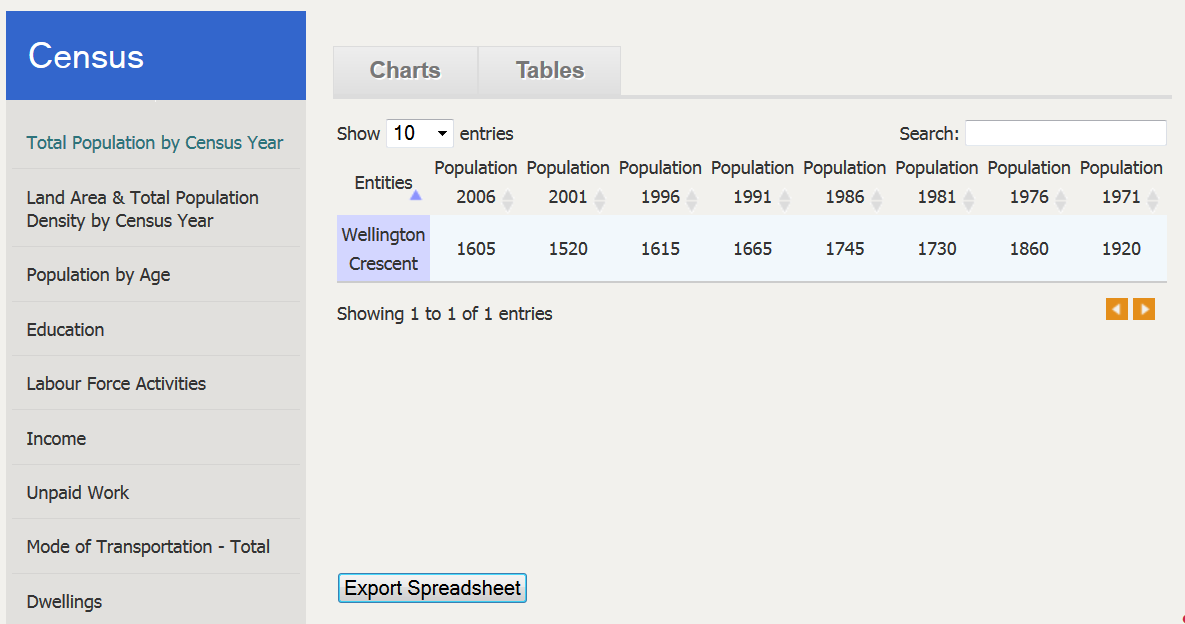
Export Census
Users also have the possibility to export census data, from the census section of the portal, in spreadsheets. They only have to select the Tables tab, and then to click the Export Spreadsheet button.
Export Ontologies
The export functionality would not be complete without the ability to consult and export the ontologies that are used to describe the content exposed by the portal. These ontologies can be read from the ontologies reader user interface, or can be exported from the portal to be read by external ontologies management tools such as Protege.
Portal Design
The portal is using Drupal 6 as its CMS (Content Management System). The Drupal 6 instance communicates with structWSF using the conStruct module, which acts as a bridge between a Druapal portal and a structWSF web service network.
Here are the main design phases that have been required to create the portal:
- Creation of the portal’s design, and the Drupal 6 theme that implements it
- Creation of the Search and Browse results templates
- Creation of the individual records’ page design and templates based on their type
- Creation of the sWebMap search results templates.
The portal’s design has been created internally by the City of Winnipeg and by Tactica based on the Citizen DAN demo. Tactica also worked on another Citizen DAN like portal called MyPeg.ca.
Semantic Components
The NOW Web portal is using a series of tools that are called the Semantic Components. These are a set of Flash and JavaScript tools that can be embedded within any web page and that can easily communicate with structWSF instance(s). They display information in all kinds of charts, they can display document reading widgets, they can create dashboards of structured data, etc. The initial set of Semantic Components was developed for the MyPeg.ca project back in November 2010. This was before Steve Jobs announced that Apple would not support Adobe Flash, and far before Google announced that it would drop support for it as well.
Since the NOW portal wanted to re-use as much as possible to lower the development cost related to the portal, they choose to use the complete OSF stack which includes these Semantic Components.
However, when we participated in developing this new NOW portal, we did extended the set of Semantic Components by creating the most complex Semantic Component: the sWebMap. However, because of the two announcements mentioned above, we choose to move forward and to create the sWebMap Semantic Component using JavaScript instead of Flash. The other Semantic Component tools that have been developed in Flash have not yet been ported into JavaScript.
Conclusion
The new NOW semantic web portal’s main asset is its data: how it can be searched (with traditional search engines or using a semantic component to search, browse, filter and localize results), displayed and exported. This portal has been developed using a completely free and open source semantic platform that has been developed from previous projects that open sourced their code.
I consider this portal a pioneer in the way municipal organization will provide new online services to their citizens and to the commercial enterprises based on the quality of the data that will be exposed via such Web portals.




