Structured Dynamics has been working with Drupal for quite some time. This week marks our third anniversary of posting code to the contributed conStruct modules in Drupal. But, what I’m able to share today is our most exciting interaction with Drupal to date. In essence, we now can run Drupal directly from an RDF triplestore and take full advantage of our broader Open Semantic Framework (OSF) stack. Massively cool!
On a vanilla Drupal 7 instance, everything ends up being saved into Drupal’s default storage system. This blog post introduces a new way to save (local) Content Type entities: the structfieldstorage field storage system. This new field storage system gives the possibility to Drupal administrators to choose to save specific (or all) fields and their values into a remote structWSF instance. This option replaces Drupal’s default storage system (often MySQL) for the content types and their fields chosen.
By using this new field storage system, all of the local Drupal 7 content can be queried via any of structWSF’s web service endpoints (which includes a SPARQL endpoint). This means that all Drupal 7 content (using this new storage system) gets converted and indexed as RDF data. This means that all of the Drupal local content gets indexed in a semantic web service framework.
Fields and Bundles
There are multiple core concepts in Drupal, two of which are Bundles and Fields. A Field is basically an attribute/value tuple that describes an entity. A Bundle is a set (an aggregation) of fields. The main topic of this blog post is a special feature of the field: their storage system.
In Drupal, each field instance does have its own field storage system associated to it. A field storage system is a system that manages the field/value tuples of each entity that has been defined as a Drupal instance. The default storage system of any field is the field_sql_storage, which is normally a MySQL server or database.
The field storage system allows a bundle to have multiple field instances, each of which may have a different field storage target. This means that the data that describes an entity can be saved in multiple different data stores. Though it may appear odd at first as to why such flexibility has merit, but we will see that this design is quite clever, and probably essential.
There are currently a few other field storage systems that have been developed for Drupal 7 so far. The most cited one is probably the MongoDB module, and there is also Riak. What I am discussing in this blog post is a new field storage system for Drupal 7 which uses structWSF as the data store. This new module is called the structFieldStorage module and it is part of conStruct.
Flexibility of the Field Storage API design
The design of having one field storage system per field is really flexible and probably essential. By default, all of the field widgets and all the modules have been created using the field_sql_storage system. This means that a few things here and there have been coded with the specificities of that field storage system. The result is that even if the Field Storage API has been designed and developed such that we can create new field storage systems, the reality is that once you do it, multiple existing field widgets and modules can break from the new field storage systems.
What the field storage system developer has to do is to test all the existing (core) field widgets and modules and make sure to handle all the specifics of these widgets and modules within the field storage system. If it cannot handle a specific widget or module, it should restrict their usage and warn the user.
However, there are situations where someone may require the use of a specific field widget that won’t work with that new field storage system. Because of the flexibility of the design, we can always substitute the field_sql_storage system for the given field dependent on that special widget. Under this circumstance, the values of that field widget would be saved in the field_sql_storage system (MySQL) while the other fields would save their value in a structWSF instance. Other circumstances may also warrant this flexibility.
structFieldStorage Architecture
Here is the general architecture for the structFieldStorage module. The following schema shows how the Drupal Field Storage API Works, and shows the flexibility that resides into the fields, and how multiple fields, all part of the same bundle, can use different storage systems:
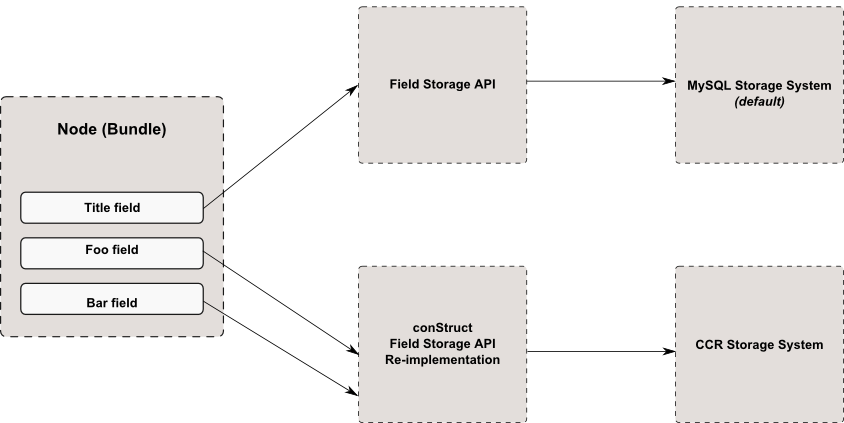
By default, on a vanilla Drupal instance, all the fields use the field_sql_storage field storage system:

Here is what that same bundle looks like when all fields use the structfieldstorage field storage system:

Finally here is another schema that shows the interaction between Drupal’s core API, structFieldStorage and the structWSF web service endpoints:

Synchronization
Similar to the default MySQL field_sql_storage system, we have to take into account a few synchronization use cases when dealing with the structfieldstorage storage system for the Drupal content types.
Synchronization with structFieldStorage occurs when fields and field instances that use the structfieldstorage storage system get deleted from a bundle or when an RDF mapping changes. These situations don’t appear often once a portal is developed and properly configured. However, since things evolve all the time, the synchronization mechanism is always available to handle deleted content or changed schema.
The synchronization workflow answers the following questions:
- What happens when a field get deleted in a content type?
- What happens when a field’s RDF mapping changes for a new property?
- What happens when a bundle’s type RDF mapping changes for a new one?
Additionally, if new field instances are being created in a bundle, no synchronization of any kind is required. Since this is a new field, there is necessarily no data for this field in the OSF, so we just wait until people start using this new field to commit new data in the OSF.
The current synchronization heuristics follow the following steps:
- Read the
structfieldstorage_pending_opts_fieldstable and get all the un-executed synchronization change operations- For each un-executed change:
- Get 20 records within the local content dataset from the Search endpoint. Filter the results to get all the entities that would be affected by the current change
- Do until the Search query returns 0 results
- For each record within that list
- Apply the current change to the entities
- Save that modified entities into the OSF using the
CRUD: Updateweb service endpoint
- For each record within that list
- Do until the Search query returns 0 results
- When the Search query returns 0 results, it means that this change got fully applied to the OSF. The state of this change record then get marked as executed.
- Get 20 records within the local content dataset from the Search endpoint. Filter the results to get all the entities that would be affected by the current change
- For each un-executed change:
- Read the
structfieldstorage_pending_opts_bundlestable and get all the un-executed synchronization change operations- For each un-executed change:
- Get 20 records within the local content dataset from the Search endpoint. Filter the results to get only the ones that would be affected by the current change
- Do until the Search query returns 0 results
- For each record within that list
- Apply the current change to the entities
- Save that changed record into the OSF using the
CRUD: Updateweb service endpoint
- For each record within that list
- Do until the Search query returns 0 results
- When the Search query returns 0 results, it means that this change got fully applied to the OSF. The state of this change record then get marked as executed.
- Get 20 records within the local content dataset from the Search endpoint. Filter the results to get only the ones that would be affected by the current change
- For each un-executed change:
The synchronization process is triggered by a Drupal cron job. Eventually this may be changed to have a setting option that would let you use cron synchronization or to trigger it by hand using some kind of button.
Compatibility
The structFieldStorage module is already compatible with multiple field widgets and external contributed Drupal 7 modules. However, because of Drupal’s nature, other field widgets and contributed modules that are not listed in this section may be working with this new field storage system, but tests will be required by the Drupal system administrator.
Field Widgets
Here is a list of all the core Field Widgets that are normally used by Drupal users. This list tells you which field widget is fully operational or disabled with the structfieldstorage field storage system.
Note that if a field is marked as disabled, it only means that it is not currently implemented for working with this new field storage system. It may be re-enabled in the future if it become required.
| Field Type | Field Widget | Operational? |
|---|---|---|
| Text | Text Field | Fully operational |
| Autocomplete for predefined suggestions | Fully operational |
|
| Struct Lookup | Fully operational |
|
| Struct Lookup with suggestion | Fully operational |
|
| Autocomplete for existing field data | |
|
| Autocomplete for existing field data and some node titles | |
|
| Term Reference | Autocomplete term widget (tagging) | |
| Select list | |
|
| Check boxes/radio buttons | |
|
| Long text and summary | Text area with a summary | Fully operational |
| Long text | Text area (multiple rows) | Fully operational |
| List (text) | Select list | Fully operational |
| Check boxes/radio buttons | Fully operational |
|
| Autocomplete for allowed values list | |
|
| List (integer) | Select list | Fully operational |
| Check boxes/radio buttons | Fully operational |
|
| Autocomplete for allowed values list | |
|
| List (float) | Select list | Fully operational |
| Check boxes/radio buttons | Fully operational |
|
| Autocomplete for allowed values list | |
|
| Link | Link | Fully operational |
| Integer | Text field | Fully operational |
| Float | Text field | Fully operational |
| Image | Image | Fully operational |
| File | File | Fully operational |
| Entity Reference | Select list | Fully operational |
| Check boxes/radio buttons | Fully operational |
|
| Autocomplete | Fully operational |
|
| Autocomplete (Tags style) | Fully operational |
|
| Decimal | Text field | Fully operational |
| Date (Unix timestamp) | Text field | Fully operational |
| Select list | Fully operational |
|
| Pop-up calendar | Fully operational |
|
| Date (ISO format) | Text field | Fully operational |
| Select list | Fully operational |
|
| Pop-up calendar | Fully operational |
|
| Date | Text field | Fully operational |
| Select list | Fully operational |
|
| Pop-up calendar | Fully operational |
|
| Boolean | Check boxes/radio buttons | Fully operational |
| Single on/off checkbox | Fully operational |
Core & Popular Modules
Revisioning
The Revisioning module is fully operational with the structfieldstorage field storage system. All the operations exposed in the UI have been handled and implemented in the hook_revisionapi() hook.
Diff
The Diff module is fully operational. Since it compares entity class instances, there is no additional Diff API implementation to do. Each time revisions get compared, then structfieldstorage_field_storage_load() gets called to load the specific entity instances. Then the comparison is done on these entity descriptions.
Taxonomy
The Taxonomy module is not currently supported by the structfieldstorage field storage system. The reason is that the Taxonomy module is relying on the design of the field_sql_storage field storage system, which means that it has been tailored to use that specific field storage system. In some places it can be used, such as with the entity reference field widget, but its core functionality, the term reference field widget, is currently disabled.
Views
structViews is a Views query plugin for querying an OSF backend. It interfaces the Views 3 UI and generates OSF Search queries for searching and filtering all the content it contains. However, Views 3 is intimately tied with the field_sql_storage field storage system, which means that Views 3 itself cannot use the structfieldstorage storage system off the shelf. However, Views 3 design has been created such that a new Views querying engine could be implemented, and used, with the Views 3 user interface. This is no different than how the Field Storage API works for example. This is exactly what structViews is, and this is exactly how we can use Views on all the fields that uses the structfieldstorage field storage system.
This is not different than what is required for the mongodb Drupal module. The mongodb Field Storage API implementation is not working with the default Views 3 functionality either, as shown by this old, and very minimal, mongodb Views 3 integration module.
structViews is already working because all of the information defined in fields that use the structfieldstorage storage system is indexed into the OSF. What structViews does is just to expose this OSF information via the Views 3 user interface. All the fields that define the local content can be added to a structViews view, all the fields can participate into filter criteria, etc.
What our design means is that the structFieldStorage module doesn’t break the Views 3 module. It does not because structViews takes care to expose that entity storage system to Views 3, via the re-implmented API.
efq_views
efq_views is another contributed module that exposes the EntityFieldQuery API to Views 3. What that means is that all of the Field Storage Systems that implement the EntityFieldQuery API should be able to interface with Views 3 via this efq_views Views 3 querying engine.
Right now, the structFieldStorage module does not implement the EntityFieldQueryAPI. However, it could implement it by implementing the hook_field_storage_query() hook. (This was not required by our current client.)
A Better Revisioning System
There is a problem with the core functionality of Drupal’s current revisioning system. The problem is that if a field or a field instance gets deleted from a bundle, then all of the values of those fields, within all of the revisions of the entities that use this bundle, get deleted at the same time.
This means that there is no way to delete a field without deleting the values of that field in existing entities revisions. This is a big issue since there is no way to keep that information, at least for archiving purposes. This is probably working that way because core Drupal developers didn’t want break the feature that enables people to revert an entity to one of its past revisions. This would have meant that data for fields that no longer existed would have to be re-created (creating its own set of issues).
However, for all the fields that uses the structfieldstorage field storage system, this issue is non-existing. Even if fields or fields instances are being deleted, all the past information about these fields remains in the revisions of the entities.
Conclusion
This blog post exposes the internal mechanism of this new structfieldstorage backend to Drupal. The next blog post will focus on the user interface of this new module. It will explain how it can be configured and used. And it will explain the different Drupal backend user interface changes that are needed to expose the new functionality related to this new module.





{kind=link}