I am giving a talk (in French) at the 85th edition of the ACFAS congress, May 9. I will discuss the engineering aspects of doing machine learning. But more importantly, I will discuss how Semantic Web techniques, technologies and specifications can help solving the engineering problems and how they can be leveraged and integrated in a machine learning workflow.
The focus of my talk is based on my work in the field of the semantic web in the last 15 years and my more recent work creating the KBpedia Knowledge Graph at Cognonto and how they influenced our work to develop different machine learning solutions to integrate data, to extend knowledge structure, to tag and disambiguate concepts and entities in corpuses of texts, etc.
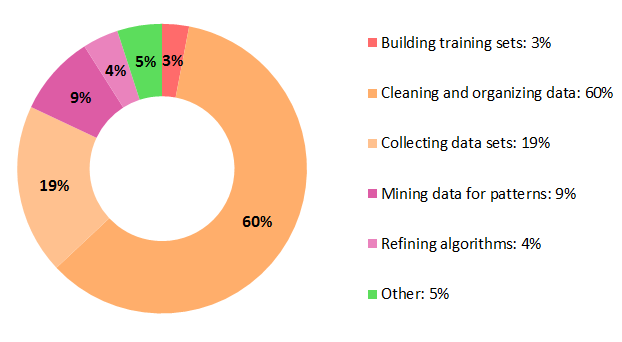
One thing we experienced is that most of the work involved in such project is not directly related to machine learning problems (or at least related to the usage of machine learning algorithms). And then I recently read a survey conducted by CrowdFlower in 2016 that support what we experienced. They surveyed about 80 data scientists to probe them to find out “where they feel their profession is going, [and] what their day-to-day job is like” To the question: “What data scientists spend the most time doing”, they answered: